신뢰할 수 있는 에이전트형 AI 시스템 구축하기
요약
Bayer AG가 제약 연구 효율성을 높이기 위해 구축한 에이전트형 RAG 시스템 'PRINCE'의 사례 연구입니다. Agentic RAG와 Text-to-SQL 기술을 활용하여 복잡한 전임상 데이터를 분석하고 신뢰할 수 있는 연구 보조 도구를 구현하는 엔지니어링 과정을 다룹니다.
핵심 포인트
- Agentic RAG 및 Text-to-SQL을 통한 지능형 연구 보조 구현
- 컨텍스트 엔지니어링을 통한 에이전트 간 정보 라우팅 최적화
- 오케스트레이션 및 관찰성을 통한 시스템 신뢰성 및 회복탄력성 확보
- 투명성과 설명 가능성을 중시하는 Human-in-the-loop 설계
신뢰할 수 있는 에이전트형 AI 시스템 구축하기
프로덕션 환경에 즉시 적용 가능한 에이전트형 AI 시스템 구축에 관한 사례 연구
본 논문은 Bayer AG가 제약 산업의 신약 개발 과제를 해결하기 위해 Thoughtworks와 함께 개발한 클라우드 호스팅 플랫폼인 Preclinical Information Center (PRINCE)를 소개합니다. PRINCE는 수십 년간의 안전성 연구 보고서를 통합하기 위해 에이전트형 검색 증강 생성 (Agentic Retrieval-Augmented Generation) 및 Text-to-SQL 기술을 활용합니다. 우리는 키워드 기반 검색에서 복잡한 질문에 답하고 규제 문서를 초안할 수 있는 지능형 연구 보조로 진화한 PRINCE의 과정을 설명합니다. 우리는 컨텍스트 엔지니어링 (context engineering)—정보가 전문화된 에이전트 간에 어떻게 형성되고 라우팅되었는지—과 하네스 엔지니어링 (harness engineering)—제어력과 신뢰성을 유지하기 위해 모델 주변에 오케스트레이션 (orchestration), 복구 (recovery), 관찰성 (observability)이 어떻게 구축되었는지—의 관점을 통해 주요 엔지니어링 결정 사항들을 되짚어 봅니다. 이 시스템은 투명성, 설명 가능성 (explainability), 그리고 인간 참여형 (human-in-the-loop) 통합을 통해 신뢰를 우선시합니다. PRINCE는 제약 분야에서 AI의 변혁적인 잠재력을 입증하며, 거버넌스와 컴플라이언스 (compliance)를 보장하는 동시에 데이터 접근성과 연구 효율성을 크게 향상시킵니다.
*
2026년 6월 16일
목차
- 과제: 전임상 데이터 미로 탐색하기
- 솔루션: PRINCE - 진화하는 플랫폼
- 시스템 아키텍처: 신뢰할 수 있는 에이전트형 RAG 시스템 엔지니어링
- 에이전트형 RAG 시스템
- 프로덕션 LLM 시스템에서의 신뢰 구축
- 회복탄력성을 위한 엔지니어링: 오류 처리 및 복구
- 데이터 품질 향상: 개체명 인식 (Named Entity Recognition) 및 주석 달기
- 계속되는 여정: 반복적 개발
- 결론
전임상 신약 개발 (Preclinical drug discovery)은 본질적으로 복잡하며 데이터 집약적입니다. 연구자들은 이 중요한 단계 동안 생성되는 방대한 양의 정보에 효율적으로 접근하고 분석해야 하는 중대한 과제에 직면해 있습니다. 종종 경직된 불리언 로직 (Boolean logic)에 의존하는 전통적인 키워드 기반 검색 방식은 전임상 연구 질문의 미묘하고 복잡한 특성에 부딪힐 때 한계를 드러내는 경우가 많습니다.
대규모 언어 모델 (Large Language Models, LLMs)의 등장은 혁신적인 기회를 제공했습니다. LLM의 생성 능력과 정보 검색 (Information retrieval) 시스템의 정밀함을 결합함으로써, 검색 증강 생성 (Retrieval-Augmented Generation, RAG)이 유망한 기술로 부상했습니다. 이 접근 방식은 전임상 데이터 접근 방식을 혁신할 잠재력을 가지고 있으며, 연구자들이 자연어로 복잡한 질문을 던지고 독점 데이터에 기반한 정확하고 맥락이 풍부한 답변을 받을 수 있게 해줍니다.
이러한 잠재력을 조기에 인식한 Bayer는 이러한 기술들이 전임상 연구의 오랜 과제들을 어떻게 해결할 수 있을지 탐구하기로 약속했습니다.
이 포스트에서는 그 여정, 즉 Bayer의 생성형 AI (Generative AI)에 대한 초기 투자가 어떻게 Agentic RAG를 기반으로 구축된 에이전트형 AI 시스템인 PRINCE로 이어졌는지를 공유하고자 합니다. 이 사례 연구는 전임상 데이터 검색을 까다로운 미로에서 직관적인 대화형 경험으로 변모시키는 과정에서의 기술적 아키텍처 (Technical architecture), 엔지니어링 결정, 그리고 학습된 교훈들을 살펴봅니다.
PRINCE 이면에 있는 많은 엔지니어링 결정들은 이제 컨텍스트 엔지니어링 (Context engineering)과 하네스 엔지니어링 (Harness engineering)의 관점에서 이해될 수 있지만, 시스템이 처음 설계되었을 당시에는 이러한 용어들을 사용하지 않았습니다. 컨텍스트 엔지니어링은 각 모델이 어떤 정보를 받고 받지 않는지, 그리고 연구 (Research), 성찰 (Reflection), 작성 (Writing)과 같은 전문화된 단계 사이에서 컨텍스트가 어떻게 이동하는지를 형성했습니다. 하네스 엔지니어링은 모델 주변의 스캐폴딩 (Scaffolding)을 형성했습니다: 오케스트레이션 (Orchestration), 도구 경계 (Tool boundaries), 상태 지속성 (State persistence), 재시도 (Retries), 폴백 (Fallbacks), 검증 (Validation), 성찰 루프 (Reflection loops), 관측 가능성 (Observability), 그리고 인간의 검토 (Human review) 등이 이에 해당합니다.
이 포스트는 기술적 아키텍처(Architecture)와 엔지니어링 과제에 초점을 맞추고 있지만, Frontiers in Artificial Intelligence에 발표된 저희의 논문에서는 제품의 진화와 비즈니스 영향에 대해 더 자세히 다룹니다.
솔루션: PRINCE - 진화형 플랫폼
이러한 과제들을 해결하기 위해, Bayer는 Preclinical Information Center (PRINCE) 플랫폼을 개발했습니다. PRINCE는 전임상(Preclinical) 데이터에 대한 통합 게이트웨이로 구상되었으며, 초기에는 이전에 고립되어 있던(Siloed) 구조화된 연구 메타데이터(Structured study metadata)를 통합하고 이를 "검색 가능한(Searchable)" 방식으로 노출하는 데 집중했습니다. 이 초기 단계에서는 사용자가 고급 필터를 적용하고 주로 구조화된 연구 메타데이터로부터 정보를 검색할 수 있었습니다.
하지만 Bayer의 가치 있는 전임상 지식 중 상당 부분은 수십 년 동안 축적된 비구조화된(Unstructured) PDF 연구 보고서 내에 존재합니다. 수년간 수많은 시스템 마이그레이션(Migration)이 이루어짐에 따라, 이러한 보고서와 관련된 구조화된 메타데이터는 불완전하거나, 누락되었거나, 심지어 잘못된 주석(Annotation)을 포함하고 있을 수도 있었습니다. 결정적으로, 권위 있는 "골드 스탠다드(Gold standard)" 정보는 승인된 PDF 연구 보고서 내에 일관되게 존재했습니다.
생성형 AI (Generative AI), 특히 RAG (Retrieval-Augmented Generation)의 등장은 이러한 풍부한 비구조화 데이터를 활용할 수 있는 핵심 열쇠를 제공했습니다. RAG 기능을 통합함으로써, PRINCE는 필터 기반의 '검색(Search)' 도구에서 자연어 기반의 '질의(Ask)' 시스템으로 패러다임을 전환하기 시작했으며, 연구자들이 이러한 연구 보고서의 내용을 직접 질의할 수 있게 했습니다.
이러한 진화는 PRINCE가 거쳐온 세 가지 뚜렷한 단계를 반영합니다:
- Search (검색): 수천 개의 비임상 연구 보고서에 대한 통합 게이트웨이를 구축하는 데 집중한 초기 단계로, 주로 구조화된 메타데이터 (metadata)를 활용하여 다양한 전임상 영역의 여러 사내 데이터 사일로 (data silos)를 검색 가능한 형식으로 통합했습니다.
- Ask (질의): 이 단계에서는 검색 증강 생성 (RAG, Retrieval Augmented Generation)을 활용한 AI 기반 질의응답 시스템을 도입했습니다. 이를 통해 연구자들은 자연어로 질문을 던짐으로써 과거 보고서의 스캔된 PDF를 포함한 비정형 데이터 (unstructured data)로부터 직접 통찰을 도출할 수 있게 되었습니다.
- Do (수행): 현재 단계는 PRINCE를 복잡한 작업을 실행할 수 있는 능동적인 연구 보조원으로 자리매김하게 합니다. 이는 멀티 에이전트 시스템 (multi-agent systems)의 통합을 통해 달성되었으며, 이를 통해 플랫폼은 복잡한 질의를 처리하고, 워크플로 (workflows)를 조율하며, 규제 문서 초안 작성과 같은 활동을 지원할 수 있습니다.
Search에서 Ask를 거쳐 Do로 이어지는 이러한 의도적인 진화는 전임상 개발 분야에서 더 높은 효율성과 혁신을 요구하는 산업계의 필요성에 대한 전략적 대응을 나타냅니다. 연구자들에게 전임상 데이터에 접근하고, 분석하며, 이를 바탕으로 행동할 수 있는 점점 더 강력한 도구를 제공함으로써, PRINCE는 더 빠른 데이터 기반 의사결정을 가능하게 하고, 불필요한 실험의 필요성을 줄이며, 궁극적으로 더 안전하고 효과적인 치료제의 개발을 가속화하는 것을 목표로 합니다.
시스템 아키텍처: 신뢰할 수 있는 에이전트형 RAG 시스템 설계
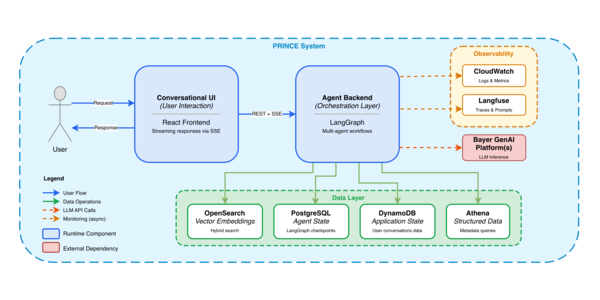
이 시스템은 강력한 백엔드 (backend) 인프라를 기반으로 작동하는 대화형 UI (UI)로 기능합니다. 복잡한 질의를 처리하고 정확하며 문맥이 풍부한 답변을 제공하도록 설계된 아키텍처는 LangGraph를 사용하여 조율되며 FastAPI 애플리케이션을 통해 서비스됩니다.
그림 1은 시스템 컨텍스트(UI, 백엔드, 데이터 저장소, LLM 폴백(fallbacks), 관측성(observability))를 제공하며, 그림 2는 시스템이 전문화된 에이전트들을 어떻게 조정하는지 상세히 보여줍니다.

그림 1: 시스템 컨텍스트 및 지원 플랫폼.
-
사용자 요청 (User Request): 프로세스는 사용자가 React로 구축된 대화형 UI (Conversational UI)를 통해 요청을 제출하면서 시작됩니다.
-
오케스트레이션 (Orchestration): 사용자의 요청은 백엔드의 LangGraph 기반 오케스트레이션 레이어로 라우팅됩니다. 이 워크플로 엔진은 사용자 의도 명확화, 사고 및 계획, 조사 수행 (RAG 및 Text-to-SQL 사용), 데이터 완성도 검증, 그리고 마지막으로 Writer 에이전트를 통한 응답 생성으로 이어지는 다단계 프로세스를 조정합니다. 이 워크플로는 다음 단계로 진행하기 전 데이터의 완전성을 보장하기 위해 의도적인 일시 중지 지점(pause points)과 피드백 루프를 포함합니다. (이 에이전트 워크플로의 세부 사항은 이후 전용 섹션에서 자세히 살펴봅니다.)
-
데이터 검색 및 상태 관리 (Data Retrieval and State Management): Researcher 에이전트들은 포괄적이고 분산된 데이터 생태계와 상호작용합니다:
- 모든 연구 보고서의 벡터 표현(Vector representations)은 OpenSearch에 저장되어 정보 검색을 위한 핵심 *지식 베이스 (knowledge base)*를 형성합니다. - 다양한 ETL 및 조화(harmonization) 프로세스의 결과물인 큐레이션된 *구조화된 데이터 (structured data)*는 Athena를 통해 액세스됩니다. - 에이전트 실행의 *상태 (state)*는 세밀하게 추적됩니다. 각 논리적 단계(LangGraph 노드 실행) 이후, 해당 상태는 LangGraph checkpointer를 사용하여 PostgreSQL에 영구 저장됩니다. - 더 넓은 범위의 *애플리케이션 수준 상태 (application-level state)*는 DynamoDB에서 관리됩니다. - 시스템은 OpenAI, Anthropic, Google 및 오픈 소스 제공업체의 모델을 호스팅하는 내부 GenAI 플랫폼을 활용합니다. 이러한 플랫폼은 모든 모델을 통합된 OpenAI 호환 엔드포인트를 통해 노출하므로, 모델을 교체하거나 각 작업에 가장 적합한 도구를 선택하기가 용이합니다. 또한 이들은 제어 평면(control plane)을 관리하며, 오남용을 방지하기 위해 속도 제한(rate limits) 및 기타 안전 장치를 강제합니다.
-
회복 탄력성 및 오류 처리 (Resilience and Error Handling): 견고함(robustness)은 핵심 설계 원칙이며, 다음과 같은 여러 폴백(fallback) 메커니즘이 마련되어 있습니다:
- 특정 LLM이 실패할 경우, 시스템은 서비스 연속성을 보장하기 위해 대체 모델이나 플랫폼으로 전환하기 전 요청을 자동으로 여러 번 재시도합니다.
-
일시적인 장애(transient failures)로부터 빠르게 복구하기 위해, 개별 LLM 호출 수준과 논리적 노드 수준(즉, 에이전트 계획의 전체 단계) 모두에서 재시도(retries)가 구현됩니다.
-
또한, 에이전트가 오류의 맥락(context)을 제공받아 이에 대한 대응으로 다른 경로를 설정하거나 대안적인 행동 계획을 수립할 수 있도록 합니다.
-
관찰 가능성(Observability) 및 평가(Evaluation): 전체 시스템의 성능과 신뢰성을 모니터링합니다:
-
일반적인 시스템 상태 및 지표는 Cloudwatch를 사용하여 추적합니다. Langfuse는 주요 관찰 가능성 도구로서 모든 프로덕션 트래픽에 대한 상세한 트레이스(traces)를 제공합니다. 이를 통해 문제에 대한 심층적인 디버깅(debugging)이 가능합니다. 또한, 평가 데이터셋이 Langfuse 내에 저장 및 관리되어 성능 점수를 분석하고 특정 실패를 진단하기가 더 용이합니다. 평가는 RAGAS 평가 프레임워크를 사용하여 수행됩니다. 라이브 트래픽 평가는 매일 수행되는 반면, 데이터셋 평가는 핵심 워크플로(workflow), 프롬프트(prompts) 또는 기반 모델(underlying models)에 중요한 변경이 발생할 때마다 수행됩니다.
-
최종 응답: 에이전트가 요청을 처리하고 만족스러운 응답을 생성하면, 이는 사용자에게 제시되기 위해 대화형 UI(Conversational UI)로 다시 전송됩니다.
이 아키텍처를 관통하는 설계 원칙은 맥락 규율(context discipline)입니다. 더 큰 컨텍스트 창(context windows)이 생겼다고 해서 각 에이전트가 무엇을 볼지 선택적으로 결정해야 할 필요성이 사라진 것은 아닙니다. 초기 반복 단계에서는 컨텍스트에 너무 많은 정보를 넣는 것이 시스템을 제어(steer)하고 평가하기 어렵게 만들었습니다. 따라서 PRINCE는 프롬프트를 사용 가능한 모든 정보를 담는 하나의 커다란 컨테이너로 취급하는 것을 피합니다. 대신, 각 단계는 서로 다른 맥락을 전달받습니다: 'Think & Plan' 단계에는 계획 맥락(planning context), 'Researcher Agent'에는 검색 맥락(retrieval context), 'Reflection Agent'에는 증거 맥락(evidence context), 그리고 'Writer Agent'에는 합성 맥락(synthesis context)을 제공합니다. 이는 맥락 오염(context pollution)을 줄이고 시스템을 디버깅, 평가 및 개선하기 더 쉽게 만듭니다.
이러한 단계들은 정교한 멀티 에이전트 아키텍처 (multi-agent architecture)와 다양하고 강력한 도구 및 데이터 소스 세트를 활용함으로써, 시스템이 광범위하고 복잡한 질의에 대해 신뢰할 수 있고 맥락적으로 관련성 있는 답변을 제공할 수 있도록 보장합니다.
에이전트형 RAG 시스템 (The Agentic RAG System)
PRINCE는 여러 단계의 과정, 추론 (reasoning), 그리고 다양한 도구 또는 데이터 소스와의 상호작용이 필요한 복잡한 사용자 요청을 처리하기 위해 에이전트형 RAG 시스템 (agentic RAG system)을 통합합니다 (그림 2). LangGraph를 사용하여 구현된 이 설정은 전체 워크플로 (workflow)를 오케스트레이션 (orchestrate)하며, 특정 작업을 위해 Researcher Agent, Writer Agent, 그리고 Reflection Agent를 활용합니다. 이 시스템은 견고하고 신뢰할 수 있도록 설계되었으며, 일부 구성 요소가 실패하더라도 시스템이 계속 작동할 수 있도록 여러 폴백 메커니즘 (fallback mechanisms)이 마련되어 있습니다.

그림 2: 연구 워크플로 (research workflow).
사용자 의도 명확화 (Clarify User Intent)
사용자 의도 명확화 (Clarify User Intent) 단계는 모호함에 대응하는 첫 번째 방어선 역할을 합니다. 시스템이 독성학 (toxicology) 및 약리학 (pharmacology)과 같은 다양한 도메인으로 확장됨에 따라, 단순한 사용자 질의가 종종 모호해져 적절한 도구를 자동으로 선택하기 어려워졌습니다. 모든 데이터 소스에 대해 비용이 많이 드는 시행착오 (trial-and-error)를 거치는 대신, 시스템은 특정 도메인이나 데이터 유형을 정확히 파악하기 위해 선제적으로 명확화 질문 (clarifying questions)을 던집니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 HN AI Posts의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기