빈티지 LLM을 밑바닥부터 만들기
요약
1800년대 런던의 텍스트 데이터만을 사용하여 밑바닥부터 학습시킨 역사적 LLM(Vintage LLM) 제작 과정을 공유합니다. Llama 아키텍처를 기반으로 한 340M 파라미터 규모의 모델을 직접 구축하며 겪은 데이터 파이프라인 및 학습 경험을 다룹니다.
핵심 포인트
- 1900년 이전의 텍스트로만 학습된 역사적 LLM 구축
- Llama 아키텍처 기반의 340M 파라미터 모델 개발
- 데이터 처리 파이프라인 및 베이스 트레이닝 스크립트 직접 구현
- 개인 PC 및 클라우드 GPU(RunPod 등)를 활용한 효율적 학습
빈티지 LLM을 밑바닥부터 만들기
이 블로그 포스트에서는 오직 오래된 텍스트로만 학습된, (거의) 밑바닥부터 저만의 LLM을 만들며 겪었던 모험을 공유하고자 합니다.
저는 저만의 베이스 트레이닝 (base-training) 및 파인튜닝 (fine-tuning) 스크립트, 데이터 처리 파이프라인 (data processing pipelines), 그리고 커스텀 데이터셋 (custom datasets)을 직접 만들었습니다.
("거의 밑바닥부터"라는 말은 기존의 프로그래밍 언어와 라이브러리를 사용했다는 뜻입니다. 어셈블리 (Assembly) 언어로 작성한 것은 아니며, 이는 AI를 "밑바닥부터" 만든다고 말하는 다른 모든 사람들과 마찬가지입니다...)
모델은 HuggingFace에서 확인할 수 있습니다: https://huggingface.co/croqaz/vintage-LLM-340m-v1-base ;
모든 코드는 다음에서 오픈 소스로 공개되어 있습니다: https://github.com/croqaz/vintage-LLM ;
더 큰 Vintage 모델들을 확인하고 싶다면, 저의 이전 포스트인 'Vintage LLM models'를 참조하세요.
아이디어
3개월 전인 2월 말, 저는 Hayk Grigorian이 자신의 temporal gated language model을 만드는 과정을 설명한 몇 개의 Reddit 포스트를 발견했습니다. 저는 완전히 매료되었습니다.
오직 1800년대 런던 텍스트로만 학습된 LLM, 90GB 데이터셋:
오직 1800년대 런던 텍스트로 밑바닥부터 학습된 LLM은 1834년의 실제 항의를 불러일으킵니다:
분명히 저는 자신만의 LLM을 만든 다른 사람들의 포스트도 읽어보았지만, 어쩌면 제가 직접 할 준비가 되지 않았었거나 그들이 작업하던 모델이 그렇게 흥미롭지 않았을 수도 있습니다. 어쨌든, 저만의 빅토리아 시대 챗봇을 갖게 된다는 생각은... 정말 끝내줍니다!!
그 이후로 저는 예외 없이 매일 저만의 "Vintage LLM" 작업을 해왔습니다. 아플 때조차도 말이죠.
그동안 Violet-1B4-Chat, Mr. Chatterbox, GPT-1900, Talkie, TypewriterLM-base와 같은 훨씬 더 많은 역사적 LLM들이 출시되었습니다.
무엇을, 왜, 어디서, 어떻게?
**무엇을? (What?)
이것은 시간 제한이 있는 LLM / 역사적 LLM (historical LLM)이며, 영어 전용이고, 지식 컷오프 (knowledge cutoff)는 1900년입니다.
(특정 연도로 제한하는 것은 오류가 발생하기 쉽지만, 최선을 다했습니다).
이 모델은 Llama 아키텍처 (architecture)를 기반으로 하며 340M (0.3B) 개의 파라미터 (params)를 가집니다.
**왜? (Why?)
직접 해봐야만 배울 수 있고, 매우 재미있는 프로젝트이기 때문입니다.
**어디서 그리고 어떻게? (Where and how?)
저는 저만의 데이터셋, 저만의 처리 및 학습 코드를 만들었습니다.
코드는 VS-Code와 PI(OpenRouter 모델)를 사용하여 제가 가지고 있던 어떤 LLM과도 반쯤 '느낌대로' 코딩했습니다.
저는 모든 단일 함수를 확인하고 검증했으며, 각 코드 파일이 무엇을 하는지 깊이 이해합니다.
데이터셋 처리에 가장 많은 시간이 걸렸고, 작동하지 않는 온갖 종류의 시도를 했으며 엄청난 시간을 낭비했습니다. 복잡한 해결책은 최악입니다...
저는 모든 데이터를 제 개인 PC에서 처리했고, 제 PC(Cachy OS Linux, AMD Ryzen 7 9700X CPU, 64GB RAM, Radeon RX 9070 16GB VRAM)에서 LLM의 작은 버전을 훈련했습니다.
더 큰 340M 모델의 경우 RunPod, ThunderCompute, Vast.ai에서 훈련했습니다. 제 PC에서는 영원히 걸렸을 것입니다.
이 프로젝트의 총 비용은 GPU 비용만으로 약 $80였습니다.
그 이유는 데이터를 처리할 만한 괜찮은 PC를 가지고 있기 때문입니다. RAM이 더 많았다면, 특히 메모리에서 텍스트를 중복 제거(de-duplicating)하는 경우 훨씬 빠르게 일부 데이터를 처리할 수 있었을 것입니다.
면책 조항: 이것은 장난감/취미 LLM이지만 (저는 이를 매우 진지하게 다룹니다).
이 모델은 환각 현상을 일으키고, 당시에는 정상으로 간주되었지만 오늘날의 기준으로는 유해하고, 불쾌하며, 안전하지 않은 역사적으로 반(semi-)정확한 콘텐츠를 생성할 것입니다. 이는 제가 어떠한 정렬(alignment)도 하지 않았기 때문에 예상되는 결과입니다. 모델을 정렬하거나 (또는 검열하는 것)에는 상당한 노력이 필요하며, 이는 역사적 정확성을 망칠 것입니다.
또한, 제가 최선을 다했더라도 제 모델이 1900년으로 엄격하게 제한된다고 보장할 수 없습니다 (예: "알베르트 아인슈타인 테스트"를 수행하는 것과 관련하여).
계획
저는 직장에서 매일 AI를 사용하며 작동 방식을 이해하지만, 스스로 LLM을 구축해 본 적은 없습니다. 과거에 직장에서 특정 AI 훈련 및 미세 조정(fine-tuning) 파이프라인을 실행했고, C와 Python으로 작은 신경망을 구축한 경험이 있지만, 이 프로젝트를 시작했을 때 사람들이 보통 어떻게 LLM을 구축하는지 알지 못했습니다.
저는 일주일 동안 검색하고 여러 봇과 대화하며 다양한 관점을 얻었습니다 (주제를 조사할 때 항상 하듯이).
요약하자면, LLM을 구축하려면 네 가지가 필요합니다:
데이터 (the data)-- LLM은 분별력이나 이해력이 없습니다. 선하거나 악한 것 등 당신이 가르치는 무엇으로부터든 학습할 것입니다. 이것이 가장 오래 걸리는 과정입니다. 토큰화 (tokenization)-- 토크나이저 (Tokenizer)는 단어나 글자를 숫자 (토큰)로 변환하는 작은 프로그램입니다. LLM은 단어를 이해하지 못하며, 오직 숫자만을 이해합니다. 사전 학습 (pre-training)-- 혼란스러운 표현이지만, 이는 LLM이 텍스트를 자동 완성하는 법을 배우는 "기초 학습 (base-training)"을 의미합니다. 만약 3억 개 (300m+) 이상의 파라미터 (params)를 목표로 한다면, 이것이 가장 비용이 많이 드는 과정입니다. 미세 조정 (fine-tuning)-- LLM이 차례대로 대화하거나 질문 및 답변을 하는 법을 배우는 단계입니다.
물론 이 단순한 단계들보다 조금 더 복잡한 부분들이 있지만, 이 글에서 아주 깊게 다루지는 않겠습니다.
이제 각 단계를 더 자세히 살펴보겠습니다.
초기 실험
제가 "큰" 모델을 결정하기 전에 많은 실수를 저질렀고, 몇몇 데이터셋 (datasets)과 모델 아키텍처 (model architectures)를 실험했다는 점을 언급할 가치가 있습니다.
("큰"에 따옴표를 붙인 이유는, 아시다시피 Talkie-13B나 TypewriterLM-7.24B 같은 더 큰 모델들과 비교하면 제 모델은 그저 장난감 수준이기 때문입니다.)
제 개인 PC에서 학습시킨 v2 장난감 모델 EleutherAI/pythia-14m에 대한 몇 가지 세부 사항입니다:
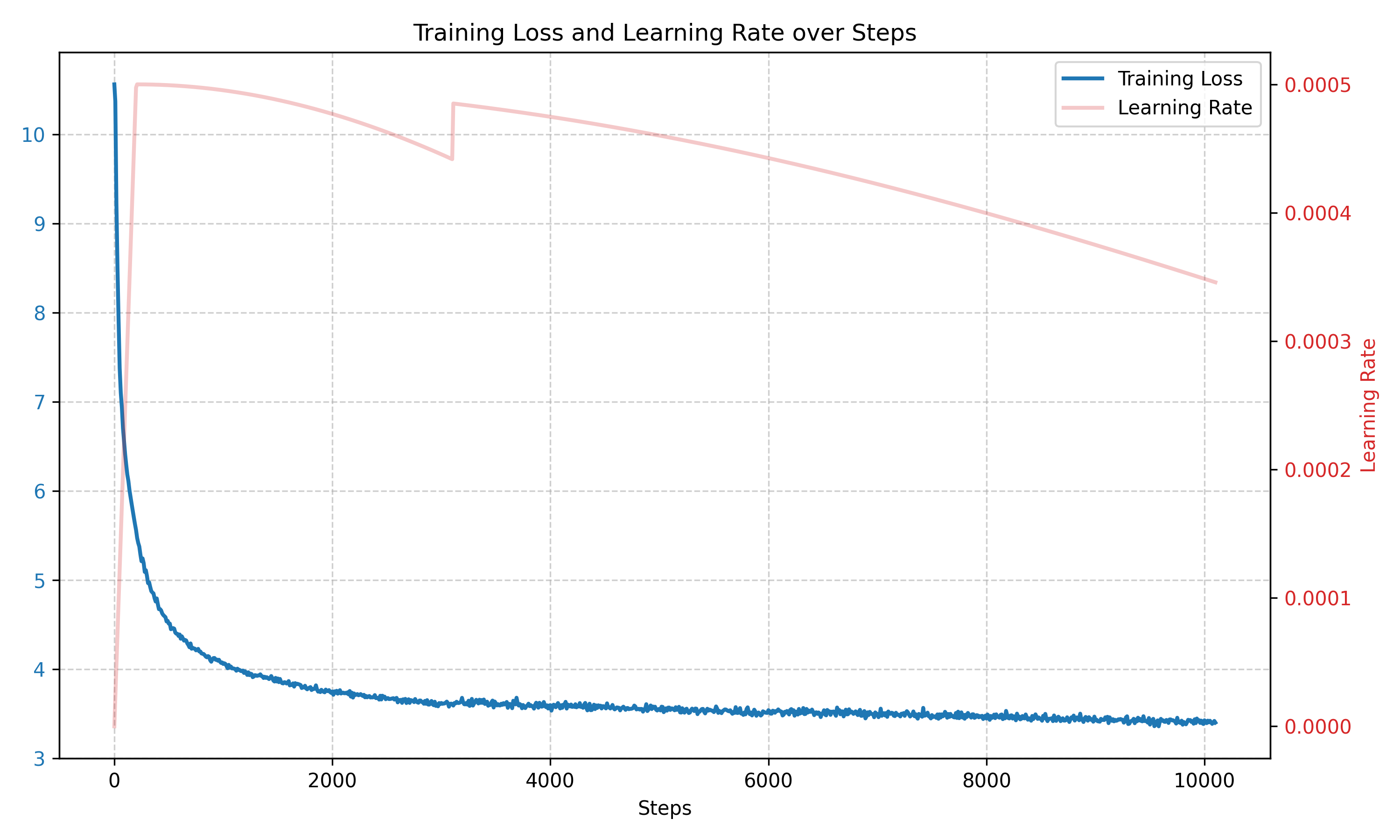
검증 손실 (validation loss) 및 퍼플렉서티 (perplexity) SVG 파일을 보면 거대한 도약이 나타나는데, 이는 제가 파일 청크 (file chunks)를 무작위로 섞지 않았고 데이터셋 파일들이 알파벳 순서로 토큰화되었기 때문입니다. 공교롭게도 깨끗한 도서 파일들이 처음에 있었고, 모델이 Time-Capsule 데이터셋에 노출되기 시작하자마자 성능이 점차 나빠졌습니다. 해당 데이터셋은 이상한 OCR 아티팩트 (artefacts), 깨진 단어 및 문장 등이 많은 나쁜 데이터셋이었기 때문입니다.
실수들이 있었습니다... 하지만 저는 그것들로부터 배웠습니다.
나쁜 문서들을 걸러내기 시작할 때까지 저는 한동안 막혀 있었습니다.
데이터
데이터 처리 (data processing)는 단연코 가장 길고 지루한 과정이었으며, 왜 그런지 여러분도 이해하시리라 믿습니다...
인터넷에서 스크레이핑(scraping)한 데이터로 구성된 현대의 고품질 데이터셋은 아주 많지만, 저는 제 LLM이 컴퓨터, 원자폭탄, 우주선에 대해 배우는 것을 원하지 않았기에 직접 만들 수밖에 없었습니다.
다행히 이용 가능한 몇몇 데이터셋이 있긴 했지만, 품질이 상당히 좋지 않았습니다. 따라서 제 작업의 대부분은 중복을 제거(de-duplicate)하고, 정말 형편없는 텍스트를 필터링(filter)하며, 기존 텍스트 중 일부를 개선(enhance)하는 작업이었습니다.
역사적 데이터셋은 상당히 제한적입니다. 우리가 더 많은 고서를 발견하고 누군가 그것을 스캔하지 않는 한, 우리에게 있는 것은 오래된 책들뿐이므로 현재 가진 것을 사용해야만 합니다.
언급할 만한 몇 가지 데이터셋은 다음과 같습니다: Project Gutenberg, Oxford Text Archive, Internet Archive books, TheBritishLibrary/blbooks, storytracer/LoC-PD-Books, dell-research-harvard/AmericanStories, dell-research-harvard/NewsWire, Heritage Made Digital Newspapers (HMD).
저는 모든 것을 1900년 이전의 영어로 제한할 수 있도록, 각 데이터셋의 연도와 언어를 찾아내기 위해 최선을 다했습니다.
안전을 위해, 품질이 좋더라도 연도가 명시되지 않았거나 텍스트 내에서 날짜를 찾을 수 없는 문서들은 완전히 무시했습니다.
사이드 프로젝트(side-project)로서, 저는 수많은 고서와 제목, 저자, 도서 ID 및 출처를 포함한 Book-Metadata HF 데이터셋을 만들었습니다: https://huggingface.co/datasets/croqaz/book-metadata ; 제 목표는 모든 Gutenberg 도서의 연도를 찾아내는 것이었지만, 연도를 100% 확신할 수 있는 책은 5,300권뿐이었습니다.
다시 말씀드리지만, 이 작업은 정말 끝도 없이 오래 걸렸으며, 이 블로그 포스트를 작성하고 있는 지금 이 순간에도 저는 아직 완전히 끝내지 못했습니다.
만약 제가 다음에 또 다른 LLM을 훈련시킨다면, 그때는 더 많고 더 좋은 데이터를 사용할 것입니다.
처음에는 MinHash와 임베딩 벡터 유사도 (embeddings vector similarity)를 포함한 여러 가지 중복 제거 (de-duplication) 방법을 사용하고 싶었습니다. 이것이 무엇을 의미하는지 모르더라도 걱정하지 마세요, 자세히 설명하지는 않을 테니까요. 하지만 그 방법들은 너무 느리고 비용이 많이 들어서 포기해야만 했습니다. 얼마나 느렸는지 맛보기로 말씀드리자면, 사양이 좋은 개발 (DEV) 서버를 사용하여 짧은 텍스트 데이터셋에 대한 임베딩 (embeddings)을 계산했는데, 서버를 밤낮으로 돌려도 일주일 동안 데이터셋의 10%밖에 처리하지 못했습니다. 서버에는 제가 공유해서 사용하던 RTX 3090 GPU 등이 장착되어 있었습니다.
결국, 저는 정규화된 텍스트 (normalized text, 모든 공백을 제거한 소문자 텍스트)를 기준으로 중복을 제거했습니다. 기본적으로 "hello world"라는 텍스트는 " Hello World "(공백과 대소문자 차이에 유의하세요)라는 텍스트와 동일하게 취급되며, 데이터셋에는 해당 텍스트가 단 한 번만 저장됩니다.
처음부터 저는 데이터가 가장 중요하다는 것을 알고 있었습니다: 쓰레기가 들어가면 쓰레기가 나옵니다 (garbage in -> garbage out). 저는 수많은 실험과 반복 과정을 거쳤으며, 데이터셋을 저장하기 위해 Qdrant, Zvec, Lance, ValKey, LevelDB와 같은 데이터베이스 (DB)들을 사용해 보았습니다.
Qdrant는 많은 항목을 추가하기도 전부터 DB 디스크 크기가 너무 커서 제외했습니다.
Zvec는 DB 항목을 순환 (cycle)할 방법이 없어서 제외했습니다. 기본적으로 한 번 저장하면 DB를 탐색할 방법이 없었습니다. 이 문제에 대해 이슈 (issue)를 생성하기도 했습니다. 또한 Zvec는 매우 최신 기술이라 성숙할 때까지 시간을 더 두고 지켜봐야 할 것 같습니다.
Lance는 버전 관리 (versioning) 문제 때문에 제외했습니다. 몇 백만 개 이상의 항목을 추가하기 시작하면 DB가 점점 더 느려집니다. 이것은 제 잘못일 수도 있으며, 더 잘할 수 있는 방법을 찾을 수 있을 것이라 확신합니다.
ValKey는 메모리 부족 (OOM, Out Of Memory) 문제 때문에 제외했습니다. 약 1,000만 개의 레코드를 주입 (ingest)한 후, 제 PC에서 서버가 OOM 크래시를 일으키기 시작했는데, 저는 훨씬 더 많은 데이터를 주입해야 하는 상황이었습니다. 그 점을 제외하면 ValKey는 정말 훌륭했습니다.
결국 저는 (로컬 지갑 앱에서 Bitcoin 및 Ethereum 트랜잭션을 저장하기 위해 사용되는) LevelDB를 사용하게 되었고, 덕분에 제 PC에서도 확장(scale)이 가능하다는 것을 알게 되었습니다. 저는 1,200만 개의 행을 아무런 문제 없이, 그리고 최소한의 CPU 및 RAM 사용량으로 주입(ingest)했습니다. LevelDB는 때때로 느릴 수 있지만, 일관되게 신뢰할 수 있습니다.
만약 제 PC 사양이 더 좋았거나 슈퍼컴퓨터가 있었다면, 아마 끝까지 ValKey를 사용했을 것입니다.
텍스트의 품질을 파악하기 위해, 저는 먼저 각 문서의 길이와 고유 문자(unique characters)를 살펴보았습니다. 첫 번째 단계에서는 짧은 텍스트(최대 32k 길이)를 사용하기로 했고, 두 번째 단계에서는 최대 10MB 길이의 긴 텍스트를 사용하기로 했습니다. 영어는 보통 30~50개의 기호(symbols)를 넘지 않아야 합니다. 만약 텍스트 청크에 100개 이상의 고유 기호가 있다면 그것은 영어가 아니므로 폐기했습니다. 그리고 만약 텍스트에 고유 기호가 8개뿐이라면 의미가 없으므로, 그것들 역시 제거했습니다.
저는 3가지 필터를 추가로 적용했습니다.
매우 쉬운 지표인 ZLIB의 압축률(compression ratio)입니다. 너무 짧고 다양성이 높은 텍스트는 큰 값을 가질 것이고, 매우 반복적인 텍스트는 아주 작은 값을 가질 것입니다.
# ZLIB 압축률 (compression ratio)
# 0.5...0.7 정도가 적당한 범위입니다;
def compression_ratio(text) -> float:
...
또한 Shannon 엔트로피(Shannon entropy)도 사용했습니다.
# Shannon 엔트로피 (Shannon Entropy)
# 인쇄된 영어의 추정 엔트로피율은 약 4.2...5.5입니다;
def char_entropy(text) -> float:
...
그리고 저만의 품질 감지 필터입니다. 이는 이상한 기호가 많은 매우 좋지 않은 OCR 텍스트를 식별하는 데 도움이 되었습니다.
_LETTER_RE = re.compile(r'[a-zα-ωàâäçèéêëîïôöùûüüÿæœß]$', re.I)
_DIGIT_SPACE_RE = re.compile(r'[0-9
]$')
_PUNCT_RE = re.compile(r'[.,;!?\''"_\-]$')
...
이러한 지표들을 계산한 후, 저는 품질이 낮은 문서들을 단순히 제거했습니다.
제거된 문서의 비율은 1% 미만이었습니다.
이 모든 실험에는 엄청난 시간이 걸렸고, 항상 제한 요소는 컴퓨팅 자원 (compute)이었습니다. 제가 처리할 수 있는 데이터셋이 몇 개 더 있긴 하지만 (예: Institutional Books 1.0, 947GB 규모의 거대 데이터셋, 983K 권의 도서, 386M 페이지 등), 제 PC를 망가뜨리고 싶지는 않으며, 제 작은 LLM을 위한 데이터는 이미 충분합니다.
제 데이터셋은 HuggingFace에서 확인하실 수 있습니다: https://huggingface.co/datasets/croqaz/vintage-v1 ;
토큰화 (Tokenization)
저는 저만의 토크나이저 (tokenizer)를 직접 만들어야 했습니다. 왜냐하면 제 모델은 "async function", "import sys", "public class Main" 또는 기타 프로그래밍 언어 용어와 같은 어휘 (vocabulary)를 전혀 필요로 하지 않을 것이기 때문입니다.
또한 이것은 영어 전용 LLM이므로, 다른 언어의 표현을 습득하는 것을 원치 않습니다.
만약 기존의 토크나이저를 사용했다면, 그 모든 쓸모없는 단어들이 어휘 공간을 낭비했을 것입니다.
저는 영어 Gutenberg 및 Oxford 도서들을 사용하여 토크나이저를 학습시켰는데, 이 데이터들이 매우 깨끗하기 때문입니다.
베이스 트레이닝 (Base-training) 1단계
기본적인 데이터셋이 준비된 후, 저는 litGPT 프레임워크를 사용하여 매우 기본적인 Pythia-14M 파라미터 (0.01B 파라미터) 모델을 빠르게 만들었습니다. 초기에는 꽤 간단하고 수월했습니다.
제 PC에서 작동하게 만들기 위해 몇 가지 트릭을 써야 했는데, 제가 Radeon GPU를 사용하고 있기 때문입니다. 대부분의 AI 학습 스크립트는 사용자가 NVIDIA GPU를 가지고 있다고 가정하니까요...
단 한 시간 만에, 저는 반무작위적인 영어처럼 들리는 횡설수설 (gibberish)을 생성하는 작은 LLM을 갖게 되었습니다. 예:
He presented them with one of the soul, which was made in the same manner ;
I have also been at this moment's, and that it was not that this month should be allowed to
be without a short time. It was not yet a word for the sake of the man who was known that he
...
그것을 가지고 조금 더 놀아본 후, 더 큰 Pythia-70M을 학습시키려 시도했으나 litGPT가 다음과 같은 오류와 함께 무작위로 충돌하기 시작했습니다:
AI 자동 생성 콘텐츠
본 콘텐츠는 HN AI Posts의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기