비엔지니어가 운영 환경에 PR을 제출하고, 하네스(Harness)가 품질을 담보한다 ── 개수(改修) 단계의 민주화 (연재 Part 5)
요약
비엔지니어가 운영 환경에 직접 PR을 제출할 수 있도록 지원하는 AI 하네스(Harness) 시스템의 사례를 소개합니다. 지식 그래프, Auto Review, Self-Healing 메커니즘을 통해 품질을 담보하며, 단순 수정을 넘어 복잡한 기능 추가까지 가능한 개발 민주화 과정을 다룹니다.
핵심 포인트
- 비엔지니어가 운영 리포지토리에 직접 PR 제출 가능
- AI 기반 Auto Review와 Self-Healing을 통한 품질 보증
- 단순 오타 수정을 넘어선 대규모 기능 추가 사례 제시
- 지식 그래프를 활용한 운영 환경의 개발 민주화
여러분 안녕하세요! 에어클로젯(airCloset)에서 CTO를 맡고 있는 츠지(辻)입니다.
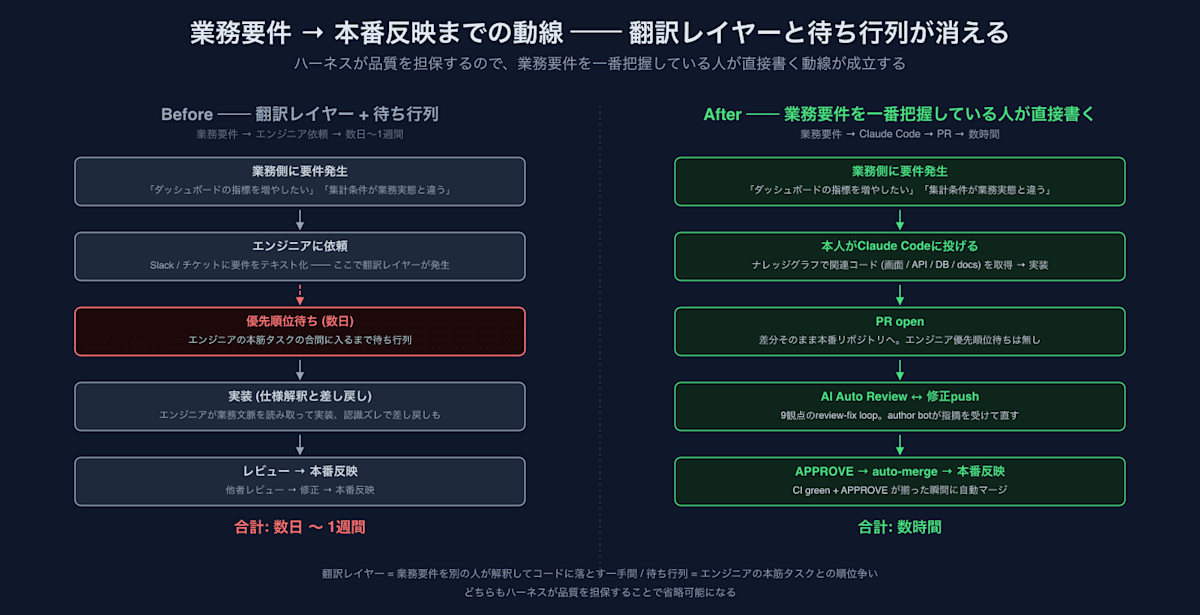
Part 1(총론)에서는 cortex의 하네스(Harness)가 구축된 결과, 엔지니어가 아닌 멤버(사업 사이드의 매니저, PMO 등)도 운영 리포지토리(Repository)에 PR(Pull Request)을 보낼 수 있게 되었다는 이야기를 썼습니다. 여기서 말하는 하네스는 AI를 운영 환경에서 구동하기 위한 토대이며, Part 1-4에서 차례로 해설해 온 지식 그래프(Knowledge Graph) / Auto Review / Self-Healing / 재발 방지의 조합을 의미합니다.
Part 5는 그 후속편으로, 그 하네스가 「누가 작성하는가」의 레이어까지 파급되고 있다는 이야기입니다.
「아니, 그래도 품질을 AI 리뷰에만 전적으로 맡겨도 정말 괜찮은 걸까」, 「결국 엔지니어가 사후에 체크하고 있는 것 아닌가」라고 생각하는 독자가 많을 것이기에, 본 기사는 우선 실례를 하나 상세하게 보여주는 것부터 시작합니다.
Part 5에서는,
어떤 PR이 실제로 머지(Merge)되고 있는가 (대표적인 2건의 내용을 구체적으로)
무엇이 가능하고, 무엇이 불가능한가 (기존 앱의 스택(Stack) 위에 얹는 작업과, 스택을 구축하는 업무의 경계선)
왜 비엔지니어라도 이것이 성립하는가 (Part 1-4에서 쌓아온 메커니즘과의 관계)
그 너머 ── cortex를 넘어 운영 환경의 toC 서비스로 (서비스 측 지식 그래프(Knowledge Graph) 구상 + 품질 수준의 차이)
를 실례를 바탕으로 정리합니다. 상세한 toC 스케일 측의 구현 이야기는 별도 기사로 분리할 예정이므로, 본 기사에서는 구상과 방향성까지 다룹니다.
연재 목록
| # | 테마 | 주요 장면 | 기사 |
|---|---|---|---|
| 1 | 총론: cortex의 하네스 | PR이 무인 머지됨 / 장애가 인지되기 전에 복구됨 | ai-harness-intro |
| ... |
갑자기 하나의 장면부터
사내 대시보드 웹 앱에 +1,742행 / 41개 파일의 PR이 올라옵니다. 타이틀은 「PL dashboard ver.2」. 내용은 여러 부문의 매니저 / 팀 리더가 자신의 부문·팀의 안건을 스코프(Scope)로 좁혀서 열람할 수 있는 기능의 추가입니다. 공유형 정의 패키지에 대한 SSoT(Single Source of Truth) 추가, API 서버 측의 신규 루트 + SQL (INNER JOIN + LEFT JOIN), 웹 앱 측의 신규 페이지 + 표시 제어 + 개인 설정 ── 한 차례 모두 포함되어 있습니다.
주목해 주셨으면 하는 점은, 이것이 「오타 수정」이나 「문자열 교체」가 아니라는 것입니다. entity / repository / API 루트 / 화면 / 필터 / 개인 설정 ── 일반적인 기능 추가 시 다루는 계층을 한 차례 모두 다루고 있습니다. 규모 면에서는 엔지니어 한 명이 며칠에 걸쳐 작성할 만한 사이즈의 PR입니다.
리뷰 왕복은 다음과 같이 진행됩니다.
PR open (+1,742 / 41 files) -
auto-review 1회차: Major 지적 (권한 스코프의 fall-through ── 자신의 부문 이외의 불필요한 정보까지 보여지는 경로) + Minor 수 건 -
author bot 수정 push: scope fall-through을 차단 + Minor 대응 -
auto-review 2회차: Nit 잔류, 추가로 lint (no-empty-function) 발견 -
author bot 수정 push: lint도 해소 -
auto-review 3회차: 여전히 세부 사항에 COMMENTED (아직 APPROVE 하지 않음) -
author bot 수정 push (iteration 2): loading skeleton 강화 + 불필요했던 JSDoc 수정의 revert -
auto-review 4회차: APPROVED → CI green + APPROVE가 갖춰진 순간 auto-merge → 운영 환경 반영
PR 오픈부터 merge까지 리뷰 왕복 4회 / 수정 push 3회, 그 사이에 인간 리뷰어는 단 한 명도 개입하지 않았습니다. 리뷰는 전부 AI(auto-review bot)가 수행하고, 수정은 PR 작성자가 구동 중인 자동 리뷰 대응 에이전트(author bot)가 대응하며, 최종적으로 AI가 APPROVE를 submit하면 auto-merge 스크립트가 이를 포착하여 merge → 배포합니다. 테스트는 공유형 정의 패키지(Type SSoT) 56/56 · API 2,284/2,284 · Web 1,113/1,113 · lint 0 errors 상태로 운영 환경에 반영하고 있습니다(cortex에서는 범용 검사를 oxlint, @graph-* 등의 독자 규칙을 eslint의 custom plugin으로 분담하고 있습니다).
특히 두 번째 리뷰에서 돌아온 지적 ── 「scope의 fall-through」 ── 는 다소 전문적이었는데, 권한 스코프(scope)에 허점이 있어 타 부서의 데이터까지 보여버리는 문제였습니다. 사내 대시보드이므로 외부 유출 인시던트는 아니지만, 「필요한 것만 보인다」는 원칙이 성립하지 않으면 불필요한 정보가 노이즈가 되어 도구의 가치가 떨어지기 때문에 이 또한 품질 게이트(quality gate)에서 걸러내는 대상입니다. 이를 첫 번째 리뷰에서 자동으로 검출하여 PR 작성자 측에 수정을 요구할 수 있다는 점이, 여기서 일어나고 있는 일의 본질에 가깝습니다. 비엔지니어가 코드를 작성하더라도, AI 리뷰가 Major급 지적을 반환하여 수정하게 만든다 ── 이 왕복 과정이 이루어지지 않는다면, 이 정도 규모의 PR을 비엔지니어에게 맡기는 것은 불가능에 가깝습니다.
그리고, 이 PR의 작성자는 엔지니어가 아닙니다. 사업 부문 멤버가 Claude Code에 "이런 화면을 만들고 싶다"라고 요구사항을 전달하고, 사내 지식 그래프(Knowledge Graph, Part 2 참조)를 통해 관련 코드를 가져오면서 +1,742행의 기능을 구현한 결과가 위의 4회 왕복입니다.
이것이 본 기사의 취지로 이어집니다 ── 업무 요구사항을 가장 잘 파악하고 있는 사람이, 요구사항을 정리하여 엔지니어에게 의뢰하는 것이 아니라, 스스로 Claude Code를 사용하여 운영 환경까지 통과시킨다.
만약을 위해 용어의 정의를 하나 두겠습니다. 본 기사에서 "작성한다"라고 말할 때, 그것은 에디터에서 한 줄씩 타이핑하는 의미가 아닙니다. 업무 요구사항을 Claude Code에 전달하고, 나온 코드 차분(diff)과 AI 리뷰의 지적을 업무 지식으로 판단하며, 운영 마진(merge)까지 가져가는 행위를 가리킵니다. 실제 차분의 대부분은 Claude Code가 작성하며, 리뷰 대응도 author bot이 수행합니다. 인간이 담당하는 것은 「무엇을 만들고 싶은지 언어화하기」, 「중간 판단(이 기능이면 충분한가 / 여기는 다르다)을 업무 지식으로 내리기」, 「최종적으로 merge할 수 있는 상태인지 승인하기」 ── 이 세 가지이며, 기술적인 구현 작업이 아니라는 의미에서 "작성한다"라고 부르고 있습니다.
물론 Claude Code에 대한 지시 방법이나 정보를 어디서 끌어올 것인가에는 다소 숙련도가 필요하겠지만, 프로그래밍을 배울 필요는 없습니다 ── 필요한 것은 「무엇을 만들고 싶은지를 언어화하는 능력」이지, syntax(구문)나 프레임워크에 대한 지식이 아닙니다.
그 상태에서 품질은 하네스(Harness)가 담보하기 때문에, +1,742행 / 41개 파일의 규모에서도 성립하고 있는 것이 위의 장면입니다.
필요해진 타이밍에, 스스로 고칠 수 있다
본 기사에서 말하고자 하는 것은,
필요해진 타이밍에, 필요한 수정을 엔지니어에게 의뢰하지 않고 스스로 할 수 있다
라는 능력이 업무 측에 성립했다는 것입니다. 이것이 성립되면,
- 대시보드에 새로운 지표를 추가하고 싶다
- 집계의 필터링 조건이 업무 실태와 맞지 않는다
- 자신을 위한 업무 지원 기능을 운영 앱의 일부로 갖고 싶다
와 같은 업무 측에서 발생하는 세세한 요구사항이 엔지니어의 우선순위 대기열(queue)에 쌓이지 않고, 그 자리에서 해결됩니다.
기존의 흐름을 떠올려 보세요. 업무 측에 약간의 수정이 필요해졌을 때, 먼저 누군가가 요구사항을 텍스트로 정리하여 엔지니어에게 Slack이나 티켓으로 의뢰합니다. 엔지니어 측은 다른 주요 태스크들 사이에서 이를 확인해야 하므로, 우선순위 내에서 며칠을 기다려야 합니다. 구현이 시작되어도 요구사항 해석이 업무 측의 인식과 어긋나 재작업(rework)이 발생하고, 리뷰가 들어가고, 최종적으로 운영 환경에 배포되기까지, 아주 작은 수정이라도 실제 시간으로 며칠에서 일주일 정도 걸리는 것이 일반적이었습니다.
이것은 업무 이해와 코드 사이에 번역 레이어(translation layer)가 끼어들기 때문에 발생하는 현상이며, 더욱이 엔지니어의 본업 태스크가 밀려 있을수록 이 지연은 길어집니다. 사업 측의 개선 사이클이 엔지니어의 바쁨에 좌우되는 구조였다고 말해도 과언이 아닙니다.
업무 요건을 파악하고 있는 사람이 직접 코드를 작성할 수 있게 되면, 위의 번역 레이어와 대기 행렬(queue)이 통째로 사라집니다.
이하, 그 능력이 성립되고 있는 실례를 살펴보겠습니다.
실제로 머지(merge)된 비엔지니어 PR ── 대표적인 2건
| PR | 종별 | 규모 | 내용 |
|---|---|---|---|
| #1573 | 버그 수정 (심층) | +348 -177 / 7 files | 대시보드의 실적 수치가 목표를 부당하게 초과하는 문제를 수정. 원인은 집계 대상 팀의 정의가 목표 측과 실적 측에서 비대칭이었던 것으로, 대상 팀의 공통 리스트를 신규 파일로 분리하여 양측을 일치시킴. 테스트(test)도 함께 추가 |
| #1557 | 기존 스택(stack)에 대규모 추가 | +1,742 -227 / 41 files | 서두에서 다룬 PL 대시보드 v2. API + UI + entity + repository까지 일일이 구현, 단 웹 앱 자체(stack)는 기존의 것을 기반으로 그 위에 얹은 추가 |
성격이 다른 2건 ── 한쪽은 데이터 정합성에 대한 심층적인 수정, 다른 한쪽은 +1,742행의 대규모 기능 구현. 둘 다 비엔지니어가 작성하여 머지(merge)까지 완료한 PR입니다.
#1573 ── 심층적인 근본 원인 수정
"숫자가 이상하다"라는 사업 측의 인지로부터, 데이터 정합성 수준의 근본 원인까지 파고든 PR입니다. 표면적인 현상은 "대시보드의 실적 수치가 목표를 부당하게 초과하여, 달성 판정이 잘못되어 101%로 표시되는 것"입니다. 보통이라면 숫자를 맞추는 계수를 추가하여 대충 넘어가거나, 표시 측에서 클램핑(clamping)하는 정도로 끝낼 법한 이야기입니다.
하지만 PR 작성자는 집계 쿼리(query)까지 파고들어 근본 원인을 다음과 같이 특정했습니다. 실적 측의 집계와 목표 측의 집계가 서로 다른 테이블을 참조하고 있었으며, "어느 팀을 집계 대상으로 할 것인가"의 정의가 비대칭이었다는 점입니다. 목표치를 가지지 않는 팀(디자이너 / PMO 등)은 목표 측 집계에는 나타나지 않는데, 실적 측에는 산입되어 있었기 때문에 실적만이 분자에 올라가 목표를 초과하게 된 것입니다.
수정은 증상이 아닌 구조를 겨냥했습니다. "집계 대상으로 하는 팀의 공통 리스트"를 1개의 파일로 분리하여, 목표 측도 실적 측도 동일한 리스트를 참조하도록 고쳤습니다. 향후 동일한 비대칭이 발생하지 않도록 공통 상수(constant)를 통해 제약하는 단계까지 수행했습니다.
집계에 포함되지 않는 데이터의 처리와 목표 / 실적의 대칭성 ── 이는 엔지니어조차 놓치기 쉬운 논점입니다. 그것을 비엔지니어가 근본 원인까지 내려가 구조 수준에서 고치고 있는 것이 이 PR의 특징입니다.
#1557 ── 기존 스택(stack) 상의 대규모 기능 구현
서두에서 자세히 다룬 PR입니다. +1,742행 / 41파일 / entity / repository / API / UI까지 갖춰진 기능 추가로, 일반적인 "개수(改修, modification)" 이미지보다 훨씬 강력한 스케일감을 가집니다.
다만 중요한 것은, 웹 앱 자체(stack)는 이미 세워져 있다는 점입니다. 새로운 앱을 구축하는 것이 아니라, 기존의 사내 대시보드에 "PL 대시보드 v2"라는 새로운 기능을 하나 추가하는 포지션입니다. Pulumi / Cloud Run / Dockerfile을 건드릴 필요도 없고, 새로운 의존성 패키지(dependency package)를 추가할 필요도 없이, 기존 디렉토리 구조 안에서 새로운 루트(route)와 페이지를 추가하여 기존의 repository pattern에 얹었을 뿐입니다.
이처럼 스택(stack) 위에 얹는 범주 안에 머물고 있기 때문에 비엔지니어도 작성할 수 있습니다. "개수(改修)"라고 부르는 이유는 바로 이러한 포지션에 머물고 있음을 말하고 싶기 때문입니다. 다음 절에서 그 경계를 깔끔하게 정리하겠습니다.
보충: 본 기사에서 "개수(改修)"라고 부르는 것은 일반적인 "기존 로직의 세밀한 수정"보다 상당히 넓은 범위를 가리킵니다. 새로운 entity / 새로운 endpoint / 새로운 페이지의 추가까지 여기에 포함하며, 스택(stack)을 구축하는 작업과 대비하여 선을 긋고 있습니다.
무엇이 가능하고, 무엇이 불가능한가
경계 설정의 원칙: 스택(stack)의 추가는 어렵다 / 스택(stack)이 있다면 추가는 가능하다
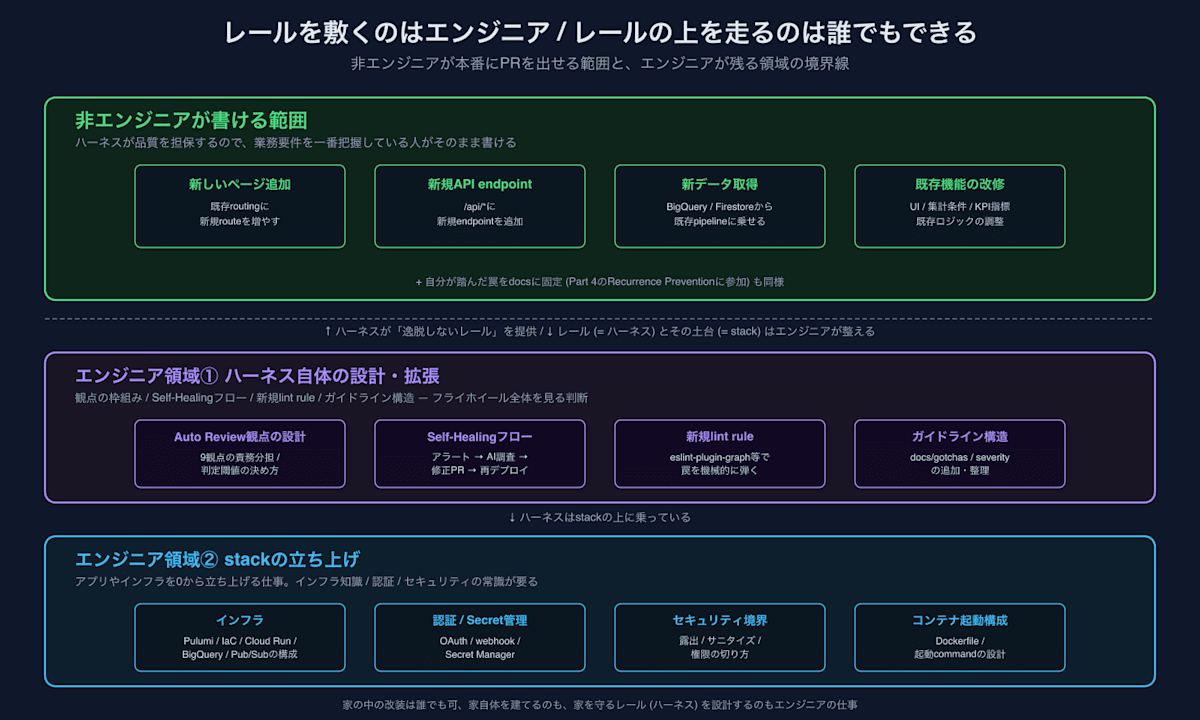
비엔지니어 개발의 경계선은 "개수(改修) vs 신규"보다, "기존 stack(스택) 위에 얹는 작업인가 / 신규 stack을 구축하는 작업인가"로 나누는 것이 실태에 더 가깝습니다.
신규 stack을 구축한다 (= 인프라부터 구축해야 하는 일. 예: 새로운 Web 앱을 하나 띄우기 / 신규로 Cloud Run 등을 Dockerfile로부터 정의하기 / 새로운 BigQuery pipeline을 처음부터 구성하기) → 엔지니어의 업무
기존 stack에 추가한다 (= 이미 있는 앱에 새로운 페이지를 만들기 / 기존 API에 endpoint를 추가하기 / 기존 pipeline에 새로운 데이터 취득을 추가하기) → 비엔지니어도 가능
직전에서 본 2건은 모두 기존 stack 위에 얹는 작업에 포함됩니다. stack 자체는 이미 본인이 만들어 놓은 것이므로, 그 내부에서 움직일 수 있습니다. 반대로 stack을 0부터 구축하는 쪽은 현재까지 비엔지니어가 다루지 않는 영역입니다.
다른 말로 하면, "집이 지어진 상태에서의 인테리어 변경이나 방 추가"는 비엔지니어 가능, "집 자체를 짓는 것"은 엔지니어입니다. 집의 구조(기둥이나 보의 배치, 배선, 배관)가 잘못되면 나중에 되돌릴 수 없는 것과 마찬가지로, stack의 설계에는 사고의 파급 범위가 큰 판단이 포함되어 있으며, 이 부분은 아직 AI에게 온전히 맡길 수 없습니다.
엔지니어가 남는 것은 "레일을 까는 쪽" ── stack 구축과, 하네스(Harness) 자체의 정비
역으로 말하면, 레일을 까는 쪽 ── stack을 구축하는 작업과, 하네스 자체를 설계·확장하는 작업 ── 은 현재까지 비엔지니어가 다루지 않는 영역입니다. 둘 다 그곳에는 별도의 영역에 대한 지식이 필요하기 때문입니다.
인프라 지식: 컨테이너 / IaC / 클라우드 서비스의 구성 및 운용 상식. Cloud Run의 리소스 상한, 콜드 스타트(Cold Start), Pub/Sub의 at-least-once 보장, BigQuery의 partition / cluster 설계, Pulumi를 이용한 스택 분할 ── 이 부분을 파악하지 못하면, 설령 동작하는 것을 만들더라도 운영 환경의 부하이나 장애 내구성 측면에서 파탄 납니다.
외부와 접속하는 인증 설계: OAuth / webhook / API 키의 취급과, 이를 Secret Manager 등에 어떻게 모을 것인가. 한 곳이라도 틀리면 인증 정보가 리포지토리에 혼입되거나, webhook으로 의도하지 않은 명령이 실행되는 영역입니다.
보안 상식: 무엇을 노출하지 않을 것인가 / 어디서 새니타이즈(Sanitize)할 것인가 / 어느 경계에서 권한을 끊을 것인가를 틀리면 운영 사고로 이어지는 영역. SQL 인젝션, XSS, SSRF, 권한 누락 ── 이 부분은 "동작하니까 OK"로 끝낼 수 없는 부분입니다.
하네스 자체의 설계·확장: Auto Review의 관점을 늘리기 / Self-Healing 로직을 바꾸기 / 새로운 lint rule (예: eslint-plugin-graph 등) 만들기 / 가이드라인의 구조 설계. 플라이휠(Flywheel) 전체가 어떻게 연결되어 있는지를 파악한 상태에서의 판단이 필요한, 가장 메타(Meta)한 업무.
마지막 "하네스 자체의 설계·확장"에는 은근히 중요한 함의가 있는데, 비엔지니어가 운영 환경에 PR을 낼 수 있는 상태를 계속 유지하기 위해서는 누군가가 하네스를 계속 진화시켜 나가야 한다는 점입니다. Part 4에서 쓴 재발 방지 루프는 사고가 발생할 때마다 lint / CI guard / 가이드라인을 늘려가는 자동적인 움직임이었지만, 하네스 자체의 아키텍처 ── 관점의 구성 / 9가지 관점의 판정 기준 / Self-Healing의 플로우 설계 / 지식 그래프(Knowledge Graph)의 구조 ── 는 별도의 메타 계층이며, 이 부분은 엔지니어의 판단이 필요합니다.
구체적인 예를 들면, 현재 9개 있는 Auto Review의 관점 ([Graph] / [Architecture] / [Security] / [Test] / [Doc] / [Impact] / [Observability] / [AI-Antipattern] / [Recurrence])의 프레임워크 자체는 과거의 사고와 수정 패턴을 관찰한 결과로서 누군가가 설계한 것입니다. 10번째 관점이 필요해졌을 때 ── 예를 들어 "의존성 패키지 업그레이드 시의 breaking change 체크"와 같은 새로운 축이 필요해졌을 때 ── 기존 관점과의 책임 분담을 어떻게 나눌지, 판정 임계치를 어떻게 결정할지는 하네스 전체의 구조를 보면서 판단해야 하는 문제입니다. 이것이 엔지니어에게 남겨진 업무의 대표적인 사례입니다.
하네스(Harness)가 제공하는 것은 "이탈하지 않는 레일"이며, 레일 자체를 까는 작업 ── 인프라를 구축하는 측도, 레일(= 하네스) 그 자체를 설계하는 측도 ── 는 별개의 업무로 남습니다. 레일을 까는 것은 엔지니어 / 레일 위를 달리는 것은 누구나 할 수 있다 ── 이것이 현재의 경계선입니다.
왜 비엔지니어도 운영 환경에 PR을 제출할 수 있는가
이 부분은 Part 1-4에서 작성한 요소들이 그대로 작용하므로, 복습 차원에서 간결하게 정리하겠습니다. **4가지 메커니즘이 서로를 강화하는 플라이휠 (Flywheel)**이 되어 있기 때문에, 비엔지니어도 기존 스택 (Stack) 위에서 안전하게 손을 댈 수 있다는 것이 결론입니다.
① 나리지 그래프 (Knowledge Graph)가 "하고 싶은 것"으로부터 관련 코드를 찾아준다
Part 2에서 작성한 코드, 문서, DB 스키마, 인프라 정의를 하나로 통합한 나리지 그래프 (구현명: cpg)가 여기서 힘을 발휘합니다.
비엔지니어가 함수명이나 리포지토리 (Repository) 구조를 모르더라도, 자연어로 "대시보드의 지표 컬럼을 늘리고 싶어"라고 Claude Code에 던지면, 나리지 그래프가 시맨틱 검색 (Semantic Search)을 통해 관련 노드 (화면 / API / DB / docs)를 1~2 홉 (Hop) 내에 가져옵니다. 기술 용어를 모르더라도 입구에 설 수 있다는 점이 큽니다.
도입부 장면의 #1557을 예로 들면, PR 작성자는 "PL 대시보드 v2에서, PMO / 팀 리더가 자기 부문·자기 팀의 안건을 필터링해서 볼 수 있게 하고 싶다"라는 요구사항을 Claude Code에 던졌고, 나리지 그래프는 기존의 /projects 루트, project-repository.ts, FilterHeaders.tsx, ProjectTable.tsx와 같은 관련 노드를 찾아왔습니다. PR 작성자는 "어떤 파일을 편집해야 하는가"를 처음부터 알 필요가 없습니다. 이것이 번역 레이어 (Translation Layer)를 제거하는 토대가 됩니다.
② Auto Review가 품질을 기계적으로 강제한다
Part 3에서 작성한 9가지 관점의 자동 리뷰 (Auto Review)가 다음 계층입니다. [Graph] / [Architecture] / [Security] / [Test] / [Doc] / [Impact] / [Observability] / [AI-Antipattern] / [Recurrence]의 9가지 관점에서 누락 사항을 REQUEST_CHANGES로 반환하며, author bot이 수정할 때까지 루프 (Loop)를 돕니다 ── 도입부 장면의 4회 왕복이 그 실례입니다.
여기서의 함의는 **"첫 번째 PR이 완벽할 필요가 없다"**는 것입니다. PR 작성자는 처음부터 보안 취약점을 메운 완성형을 작성할 필요가 없으며, 첫 번째 PR만 제출하면 나머지는 자동 리뷰와 author bot의 왕복을 통해 완성됩니다. author bot이 지적 사항을 잘못 해석하여 "무한히 계속 수정하는" 식의 미궁에 빠지지 않는 이유는, 나리지 그래프가 코드베이스 전체의 컨텍스트 (Context)를 유지하고 있으며, 수정 범위를 구조적으로 파악한 상태에서 대응할 수 있도록 설계되어 있기 때문입니다.
③ Self-Healing이 사고가 발생했을 때의 후처리를 담당한다
Part 4에서 작성한 Self-Healing이 세 번째 계층입니다.
만일 운영 환경 (Production)에서 이상이 발생하더라도, AI가 알람 (Alert)을 기점으로 원인 조사 → 수정 PR → 자동 재배포 (Auto Re-deployment)로 완결합니다. 비엔지니어가 일으킨 사고도 사람의 손을 거치지 않고 복구할 수 있으므로, 운영 환경에 PR을 제출하는 심리적 장벽이 크게 낮아집니다.
이는 "비엔지니어도 쓸 수 있으니까 안전하다"라는 주장이 아니라, "작성한 후에 무언가 일어나더라도 하네스가 잡아낸다"라는 사후 안전망이 존재하기 때문에 입구를 넓힐 수 있다는 전제가 성립한다는 이야기입니다. 실패 가능성을 제로로 만드는 방향이 아니라, 실패하더라도 데미지를 최소화하는 방향으로 설계되어 있습니다. Part 4의 3층 구조 (Observation → Repair → Strengthening)가 바로 이 사후 안전망의 내용입니다.
④ 재발 방지 루프로 함정이 늘어나지 않는다
마지막으로, Part 4 후반부에서 작성한 재발 방지 루프입니다.
한 번 빠진 함정은 동일한 PR 내에서 고착화되므로, 다음에 같은 패턴을 작성하려고 해도 차단됩니다. 고착화 수단은 패턴에 따라 다르며, 기계적으로 판정할 수 있는 것은 lint / CI guard, 기계화가 어려운 것은 가이드라인 문서 (docs/gotchas
또는 severity(심각도) 문서)에 작성하고 AI 리뷰어가 이를 포착한다 ── 어떤 형태든 merge(병합) 전에 검출됩니다. 비엔지니어 자신도 자신이 빠진 함정을 docs(문서)에 추가하는 방식으로 이 루프에 참여할 수 있는 구조로 되어 있습니다.
이것이 효과를 발휘하기 시작하면, 하네스(Harness)의 레일은 시간이 지남에 따라 정교해집니다. 처음에는 "이곳을 지나가면 안 된다"라는 대략적인 선밖에 없던 곳에, 사고를 겪을 때마다 "여기도, 여기도, 여기도"라며 가는 선들이 추가되어 결과적으로 "길을 잃기 어려운 레일"이 만들어집니다. 비엔지니어에게는 레일의 밀도가 높을수록 안전하게 달릴 수 있는 ── 그런 구조로 되어 있습니다.
→ 이 네 가지는 독립된 부품이 아니라, 서로의 출력이 서로의 입력이 되는 설계입니다. Part 1의 Guides + Sensors의 플라이휠(Flywheel) 이야기와 같습니다. 상세한 내용은 각각의 기사에 적혀 있으므로 깊게 다루지는 않겠지만, 비엔지니어가 운영 환경에 PR을 제출할 수 있는 현상은 이 네 바퀴가 동시에 돌아가고 있기 때문에 비로소 성립합니다. 하나라도 빠지면 작성자에게 요구되는 전제 지식이 단번에 늘어나 금방 무너지고 맙니다.
그 너머 ── cortex의 밖으로, 운영 toC 서비스로
cortex는 사내 AI 기반이므로, 지금까지의 메커니즘을 운영 toC 서비스에 그대로 가져올 수는 없습니다. 가장 큰 논점은 품질 기준의 차이입니다 ── toC는 사용자 영향이 나타난 후에 검지 → Self-Healing(자가 치유)으로 복구하는 방식으로는 너무 늦습니다. 사고가 일어나지 않는 것, 설령 일어나더라도 사전에 검증과 리뷰가 완료된 상태에서 인간이 sign-off(승인)하고 있는 것이 요건이 됩니다.
다만, 하네스의 형태 ── 지식 그래프(Knowledge Graph)로 컨텍스트(Context)를 맞추고, 9관점 AI 리뷰를 통과하며, author bot이 지적에 대응하는 것 ── 은 동일한 구조로 가져올 수 있습니다. 다른 점은 최종 단계뿐이며, cortex의 auto-merge(자동 병합)를 "AI 사전 준비 + 인간 sign-off"로 변형하는 것입니다. AI에게 맡기는 범위를 줄이는 것이 아니라, AI가 전단(테스트 작성 / 테스트 환경 구축 / 테스트 실행 / 9관점 리뷰)을 모두 마친 상태에서 인간이 최종 APPROVE(승인)를 누르는 형태로 만들면 됩니다. "인간이 sign-off를 한다면 엔지니어의 시간이 줄어들지 않는 것 아닌가"라고 생각하실 수도 있지만, 기존에 엔지니어가 시간을 사용하던 "구현 + 테스트 작성 + 환경 준비 + 자기 리뷰 + 타인 리뷰 대응" 중 sign-off는 마지막의 작은 부분입니다. AI가 전단의 대부분을 담당하는 만큼, 엔지니어의 업무 내용은 구현 작업에서 품질 판단 측면으로 시프트(Shift)됩니다.
참고로 컨텍스트 해결을 위해 지식 그래프가 필요한 것은 코드베이스가 대규모가 된 이후입니다. AI가 하나의 컨텍스트에 코드 전체를 읽을 수 있는 사이즈라면 횡단 그래프는 필요 없으며, cortex (100+ apps)나 운영 toC (40+ repos) 규모이기 때문에 효과가 있는 이야기입니다.
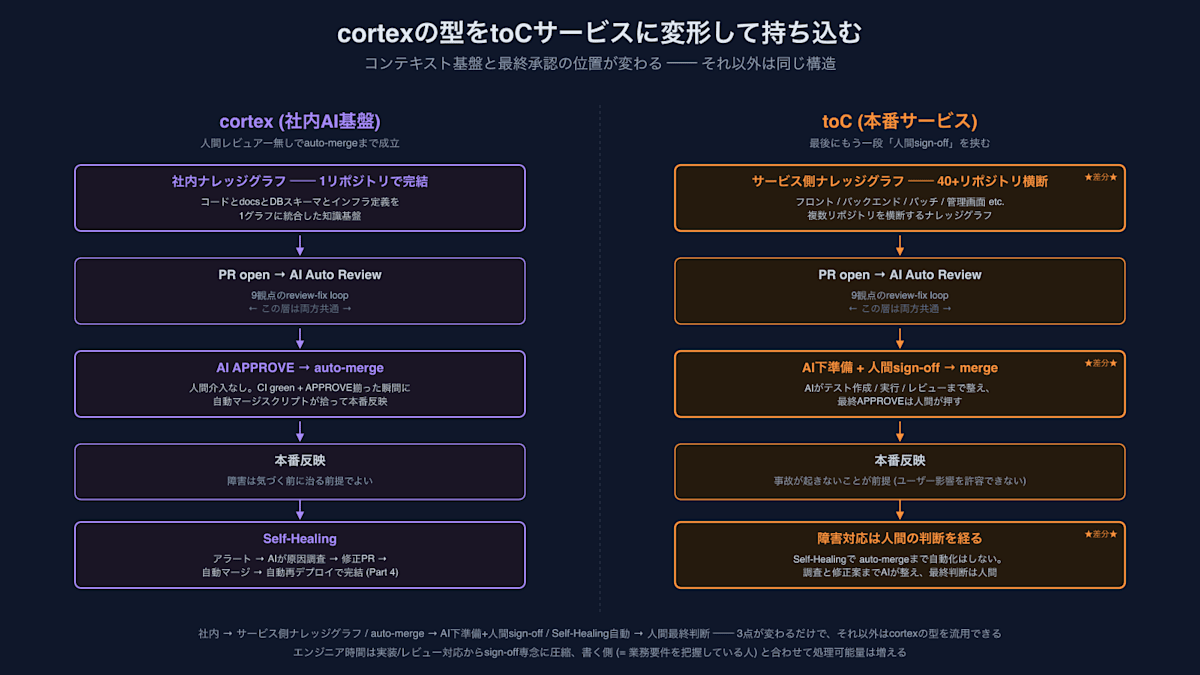
구체적인 구상은 진행 중이며(cortex의 지식 그래프를 toC 측 40+ 리포지토리에 횡단 전개하는 것, AI 사전 준비 플로우 설계 등), 상세한 내용은 별도의 기사로 다룰 예정입니다.
요약
업무 요건을 가장 잘 파악하고 있는 사람이 요건을 정리하여 엔지니어에게 의뢰하는 것이 아니라, 직접 그대로 작성한다. 품질은 하네스가 담보하므로, 작성자에게 요구되는 것은 업무 이해와 AI를 활용하는 능력만으로 충분하다. 결과적으로 업무 측의 세세한 요구사항이 엔지니어 대기열에 정체되지 않고 사업 속도가 올라간다. 이를 뒷받침하는 것은 Part 1-4의 네 가지 메커니즘(지식 그래프 / Auto Review / Self-Healing / 재발 방지)의 플라이휠.
-
첫 PR에서 완벽할 필요가 없으며, 틀려도 알아서 수정되는 설계. 경계선은 "
-
레일을 까는 것은 엔지니어 / 레일 위를 달리는 것은 누구나 할 수 있다". 인프라 / 인증 / 보안을 요하는 stack(스택)의 구축, 그리고 하네스 자체의 설계 및 확장(lint rule 추가 / Auto Review 관점 설계 / Self-Healing 플로우 개선 등)은 여전히 엔지니어의 업무.
-
이 형태를 운영 toC 서비스로 확장할 경우, 컨텍스트는 서비스 측의 지식 그래프(40+ 리포지토리 횡단)로 해결할 수 있지만, 품질 수준이 다르므로 auto-merge가 아닌 "AI 사전 준비 + 인간 sign-off"로 변형하여 도입한다. 상세 내용은 별도 기사
다음 Part 6는 연재 전체의 총괄입니다. 핵심은 애초에 어떤 사상(Philosophy)으로 이것을 수행하고 있는가 ── 무엇을 버리고 무엇을 취했는지, 왜 이러한 설계(Design)를 선택했는지와 같은 토대(Foundation)에 관한 이야기입니다. 아울러, 지금까지의 기사에서는 '원활하게 돌아가고 있는 결과'를 중심으로 써왔기에, 그 이면에서 겪었던 실패와 시행착오도 되돌아보며 사상과 구현(Implementation) 사이의 간극도 정리하고자 합니다. 저 자신의 회고이기도 하며, 비슷한 일을 시작하려는 분들에게 참고가 되기를 바라는 마음입니다.
제가 CTO로 재직 중인 주식회사 에어클로젯(AirCloset)에서는 AI와 함께 새로운 개발 경험을 만들어 나갈 엔지니어를 모집하고 있습니다. 관심 있는 분들은 꼭 엔지니어 채용 사이트인 에어클로퀘스트(AirCloset Quest)를 확인해 주세요!
Discussion
AI 자동 생성 콘텐츠
본 콘텐츠는 Zenn AI의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기