
법률 에이전트를 위한 효율적인 검증기(Verifier) 설계
요약
법률 에이전트의 성능 평가 및 강화학습 시 발생하는 검증 비용 문제를 해결하기 위한 효율적인 검증기 설계 방안을 다룹니다. 배치 처리와 오픈 모델 활용을 통해 검증 비용을 최대 10배 절감하고 프롬프트 튜닝으로 정밀도를 높이는 방법을 제안합니다.
핵심 포인트
- 검증기 배치 처리를 통해 LLM API 호출 비용을 획기적으로 절감 가능
- 오픈 모델 활용 시 프론티어 모델 수준의 성능을 유지하며 비용 10배 절감
- 프롬프트 튜닝을 통해 특정 법률 동작에 대한 검증 정밀도 향상
- 복잡한 법률 도메인 에이전트 평가를 위한 효율적 워크플로우 제시
핵심 요약 (Key Takeaways)
- 검증기(Verifier)는 에이전트 평가 및 대규모 강화학습 (RL) 사후 학습 (post-training)을 실행할 때 비용 병목 현상이 될 수 있습니다.
- 검증기를 배치(batching) 처리하고 오픈 모델(open models)을 사용함으로써 검증 비용을 10배(an order of magnitude)까지 줄일 수 있음을 확인했습니다.
- 검증기를 위한 프롬프트 튜닝(Tuning prompts)을 통해 특정 동작을 더욱 정밀하게 타겟팅할 수 있습니다.
저자: Vivek Trivedy (LangChain), Jake Broekhuizen (LangChain), Harrison Chase (LangChain), Niko Grupen (Harvey), Gabe Pereyra (Harvey), Spencer Poff (Harvey), Julio Pereyra (Harvey)
이번 달 초, Harvey는 복잡한 법률 업무에서 에이전트를 평가하기 위한 오픈 소스 벤치마크인 LAB를 출시했습니다. 초기 결과에 따르면, 오늘날의 에이전트들이 법률 업무를 수행하기에는 아직 갈 길이 멀다는 것을 보여줍니다.
우리는 Harvey와 함께 다음과 같은 질문을 다루었습니다:
법률 에이전트 작업의 정확성을 어떻게 더 효율적으로 검증할 수 있을까?
이것이 왜 중요할까요? 법률 업무는 컨텍스트(context)를 가득 채우는 수많은 문서가 존재하고, 전문 지식이 필요하며, 결과물이 수용 가능하기 위해 준수해야 할 엄격한 기준이 있기 때문에 에이전트에게 특히 어려운 도메인입니다.
LAB 벤치마크는 인간 검토자가 하는 방식과 매우 유사하게 검증에 접근합니다. 데이터셋의 모든 작업에는 작업 통과를 위해 반드시 충족해야 하는 일련의 **기준 (criteria)**이 있습니다. 각 기준은 검증기 모델(verifier model)을 사용하는 개별 LLM 판사(LLM judge)에 의해 평가됩니다. 각 기준에 대해, 검증기는 에이전트의 출력값과 측정해야 할 match_criteria를 전달받습니다. 그리고 기준당 하나의 verdict (판결)를 출력합니다. 많은 작업이 검증해야 할 50개 이상의 개별 기준을 가지고 있습니다. 이러한 각 기준마다 LLM API 호출을 수행하는 것은 프론티어 모델(frontier models)을 사용할 경우 규모가 커짐에 따라 비용이 매우 많이 듭니다.

더 효율적인 검증을 수행할 수 있을까?
프론티어 검증기를 실행하는 비용은 법률 에이전트 평가를 수행하거나 RL로 법률 에이전트를 학습시키는 팀들에게 실질적인 질문을 던집니다:
프론티어 모델의 성능에 근접하면서도 검증 비용을 최적으로 줄이는 방법은 무엇인가?
우리는 더 효율적인 검증을 수행하기 위한 두 가지 서로 다른 방법을 연구합니다:
- 더 적은 토큰 사용 (Use fewer tokens)
- 더 저렴한 토큰 사용 (Use cheaper tokens)
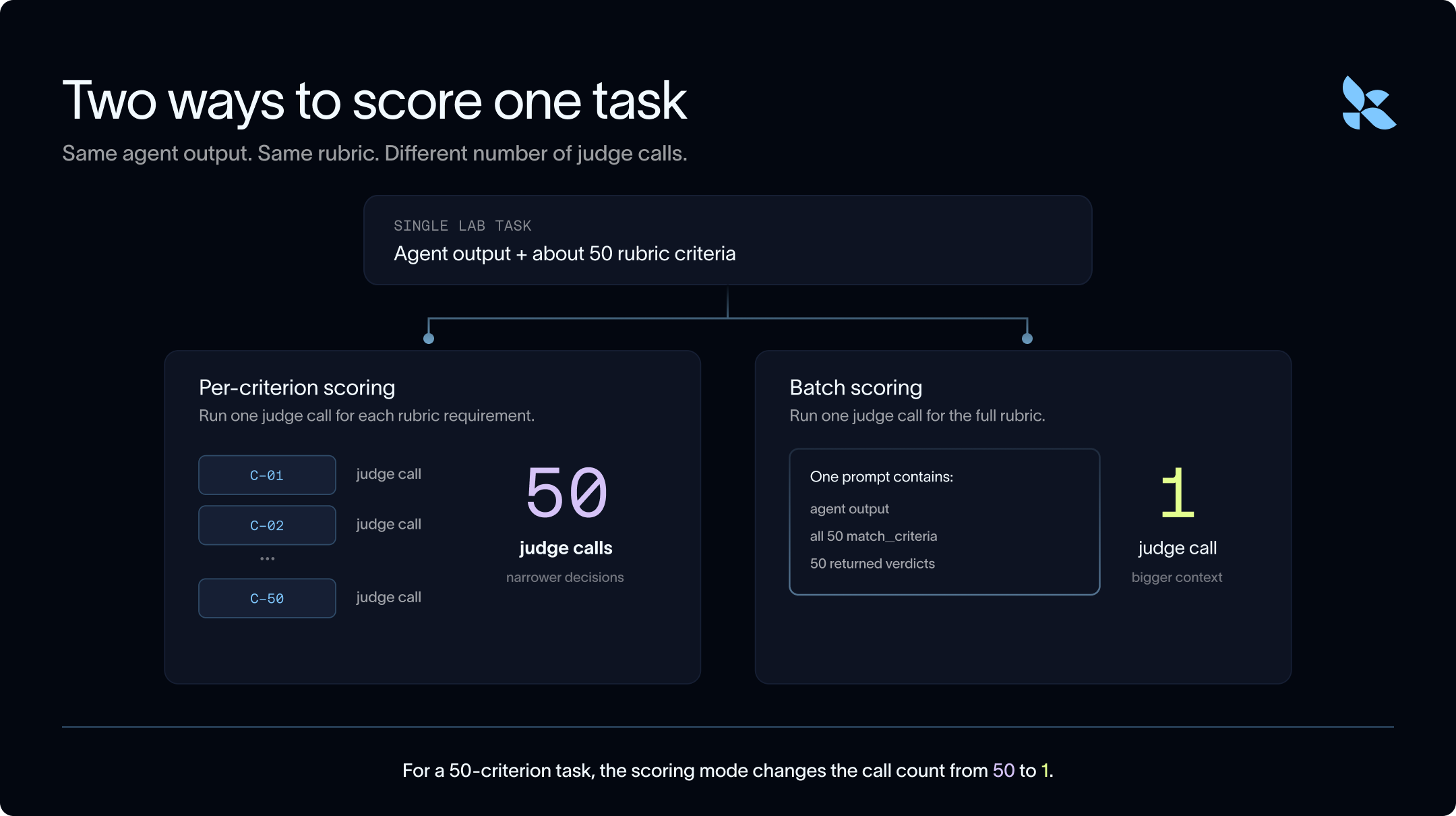
우리가 탐구하는 첫 번째 방법은 더 적은 토큰을 사용하는 것입니다. 더 적은 토큰을 사용하기 위해, 우리는 검증기(Verifier)를 배치(Batch)로 실행할 것을 제안합니다. 즉, 각 기준(Criterion)에 대해 독립적으로 LLM 호출을 사용하는 대신, 단일 배치 호출로 전체 루브릭(Rubric)을 판단하도록 요청할 수 있습니다.
기준별 점수 산정 (Per-criterion scoring): 각 루브릭 요구 사항에 대해 하나의 판단(Judge) 호출을 실행합니다.
배치 점수 산정 (Batch scoring): 작업에 대해 하나의 판단 호출을 실행하고, 판단 모델이 모든 루브릭 요구 사항을 한 번에 라벨링하도록 요청합니다.
우리가 탐구하는 두 번째 방법은 더 저렴한 토큰을 사용하는 것입니다. 더 저렴한 토큰을 사용하기 위해, 검증 과정에서 더 저렴한 모델들을 테스트할 수 있습니다. 우리는 Opus 4.7의 기준별 점수 산정을 기준으로 삼았으며, GPT-5.5, Sonnet 4.6, DeepSeek v4 Flash, 그리고 Claude Haiku 4.5를 기준별 점수 산정 및 배치 점수 산정 방식 전반에 걸쳐 비교했습니다.
검증기 설계별 효율성 측정을 위한 실험
검증기 실험을 수행하기 위해, 우리는 먼저 검증기가 평가할 출력값 세트를 생성해야 했습니다. 이러한 출력값을 만들기 위해, 우리는 기업 인수합병(Corporate M&A), 세무(Tax), 신생 기업/벤처 캐피털(Emerging Companies/VC), 그리고 신탁 및 유산(Trusts and Estates) 분야에 걸친 40개의 공개 LAB 작업에 대해 에이전트(Kimi K2.6 기반)를 실행했습니다.
이 40개의 작업에는 2,348개의 개별 루브릭 기준이 포함되어 있으며, 각 기준은 검증기에 의해 합격/불합격(Pass/Fail)으로 점수가 매겨집니다. 우리는 먼저 모든 기준에 대해 Opus-4.7을 실행하여 베이스라인(Baseline)을 설정했습니다. 이를 통해 다른 검증 옵션인 GPT-5.5, Sonnet 4.6, Haiku 4.5, DeepSeek-V4-Flash를 테스트할 때 비교할 수 있는 기준점을 확보했습니다. 모든 검증 실행은 동일한 2,348개의 기준 점수(합격/불합격)를 생성하며, 우리는 이를 사용하여 모델 간의 비교 연구를 수행할 수 있습니다.
각 검증 실행에 대해 우리는 다음 항목들을 측정했습니다:
일치도 (Agreement): Opus의 기준별 라벨과 얼마나 자주 일치하는지
오탐 합격 (False pass): Opus가 불합격 처리한 기준을 얼마나 자주 합격 처리하는지
오탐 불합격 (False fail): Opus가 합격 처리한 기준을 얼마나 자주 불합격 처리하는지
비용 (Cost): 40개 작업 검증 실행 시 관찰된 토큰 비용
우리는 잘못된 통과 (false passes)에 특히 주의를 기울였습니다. 실제 환경에서는 기준 미달 시 추가 검토를 위해 에스컬레이션 (escalation)할 수 있습니다. 법률과 같은 도메인에서는 기준을 통과시키지 말아야 할 상황에서 통과시키는 것보다, 기준 미달로 처리하는 것이 대개 더 바람직합니다.
대부분의 에이전트 시스템 설계와 마찬가지로, 검증 (Verification)은 성능 (performance), 비용 (cost), 그리고 시간 (time) 사이의 트레이드오프 (tradeoff)입니다. 기준별 검증 (Per-criterion verification)은 판독자 (judge)에게 더 좁은 결정 범위를 제공하지만, 훨씬 더 많은 호출 (calls)을 필요로 합니다. 배치 검증 (Batch verification)은 더 저렴하고 빠르지만, 판독자가 전체 루브릭 (rubric)을 한 번에 추적해야 합니다.
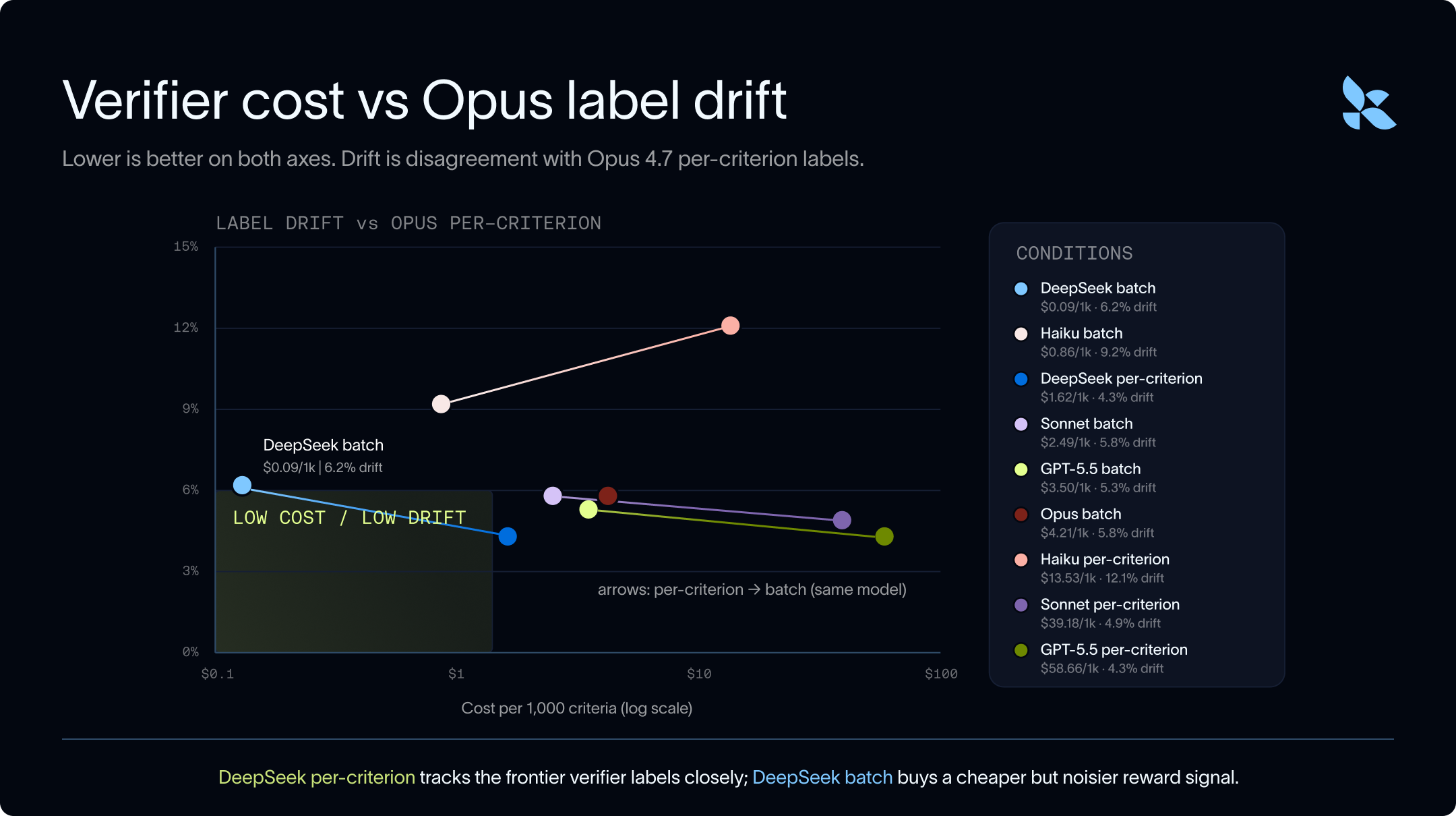
아래 차트는 비용 대비 라벨 드리프트 (label drift)를 보여줍니다. x축은 루브릭 기준 1,000개당 검증 비용입니다. y축은 기준별 라벨에 대한 Opus와의 불일치, 즉 100% - 일치율 (agreement)입니다.
그래프가 낮고 왼쪽일수록 더 좋습니다.
주요 시사점:
- 전반적으로, 배치 모드 (batch mode)로 실행하는 것이 기준별 모드 (per-criterion mode)로 실행하는 것보다 일치율 (match rates)이 낮습니다. 하지만 배치는 동일한 모델을 사용할 때 반복적인 입력 토큰 (input token) 비용을 절감하므로 실행 비용이 한 자릿수(order of magnitude)만큼 더 저렴합니다.
- GPT-5.5 및 Opus와 같은 프런티어 모델 (frontier models)조차 라벨에 대해 의견이 일치하지 않으며, 일치율은 95.7%에 불과합니다. 이는 일부 데이터 포인트가 모델이 전문가만큼 일관되게 적용할 수 있을 정도로 충분히 구체화되지 않았을 수 있음을 의미합니다. 또한 이는 100% 일치율을 목표로 하는 것이 비현실적일 수 있으며, 95.7%의 일치율이 합리적인 상한선일 수 있음을 의미합니다.
- DeepSeek는 기준을 하나씩 실행할 때나 배치 모드로 실행할 때 모두 Opus의 검증기로서 강력한 근사치 (approximation)를 보여줍니다. 또한 3 자릿수(orders of magnitude)만큼 더 저렴하게 실행할 수 있어, 대규모 검증을 실행해야 하는 대량 데이터 및 학습 도메인에서 좋은 후보가 됩니다.
- Haiku는 Opus 및 Sonnet보다 저렴했지만, 훨씬 더 관대했습니다. Haiku의 잘못된 통과 (false-pass) 비율은 기준별로 48.4%, 배치로 34.7%였으며, 이는 법률 검증에서 잘못된 실패 모드 (failure mode)입니다.
사후 학습 (post-training)에서의 비용 절감
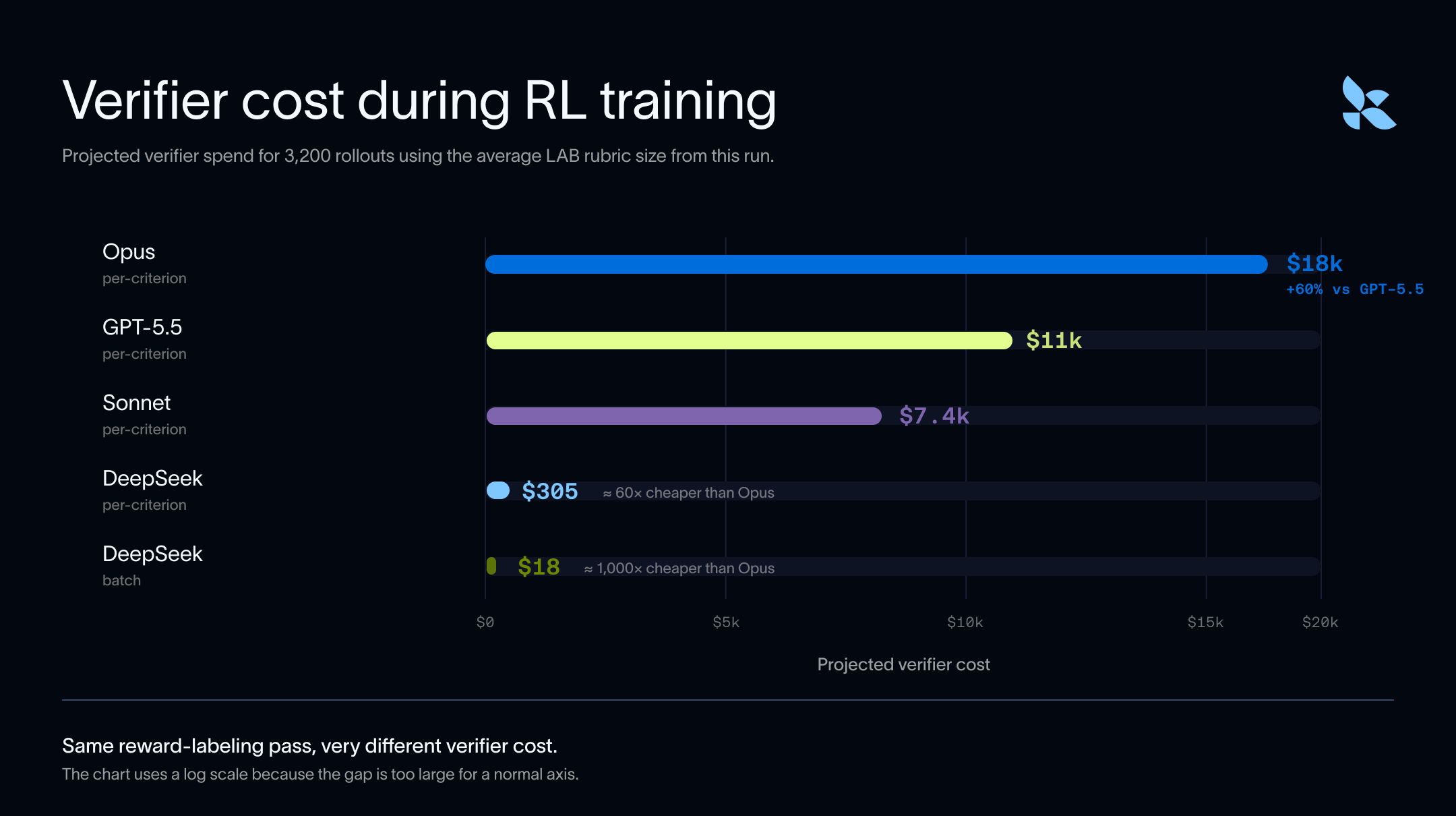
검증기 (Verifiers)는 단순히 평가 (evals)를 위해서만 사용되는 것이 아닙니다. 검증기는 사후 학습 (post-training)에도 사용되며, 작업당 여러 번의 롤아웃 (rollouts)이 발생하기 때문에 여기서 검증 비용이 증폭됩니다. LLM-as-judge 시스템은 작업 루브릭 (task rubrics)을 보상 신호 (reward signals)로 변환하며, 더 저렴한 보상 신호는 더 많은 실험을 수행하고, 더 많은 롤아웃을 감사하며, 더 빠르게 반복 (iterate)하는 것을 실질적으로 가능하게 합니다.
비용을 추정해 본 결과, DeepSeek는 대규모 환경에서 프런티어 검증기 (frontier verifiers)보다 60~1000배 더 저렴하게 실행될 수 있음을 보여줍니다. 이는 프로그래밍 방식으로 쉽게 검증할 수 없으며, 보상 신호를 생성하기 위해 일정 수준의 LLM-as-a-Judge가 필요한 도메인에서 특히 중요해집니다.
트레이스 (Traces)를 통한 검증기 동작 튜닝
결과값은 모델 및 검증기 아키텍처(기준별 (per-criterion) vs 배치 (batch))에 대해 프롬프트 (prompt)를 고정하여 유지했습니다. 우리가 테스트한 추가적인 레버 (lever) 중 하나는 타겟 프롬프트 튜닝 (targeted prompt tuning)이었습니다.
프롬프트 튜닝의 효과를 테스트하기 위해, 우리는 Opus와 비교한 DeepSeek의 이전 결과에 대해 자동 연구 루프 (auto-research loop)를 실행했습니다. 우리는 DeepSeek가 왜, 그리고 어떻게 차이가 발생하는지 살펴보고 여러 차례의 실행을 통해 프롬프트를 미세 조정했습니다. 우리는 DeepSeek에게 오판 통과율 (false-pass rate)을 최적화하도록 지시했습니다.
기본 프롬프트를 사용했을 때 DeepSeek에서 발생한 일부 오류의 주요 원인 중 하나는, 정답이 요구 사항과 관련은 있지만 모든 실질적인 부분을 충족하지 못할 때 DeepSeek가 기준을 통과시키려는 경향이 너무 강했다는 점입니다. 최종 프롬프트는 검증기가 각 기준의 각 요소를 체크리스트로서 더 명시적으로 분해하도록 만들었으며, 제시된 정보가 완전히 명확하지 않을 경우 주의를 기울이도록 지시했습니다. 이를 통해 두 가지 점수 산정 모드 모두에서 DeepSeek의 오판 통과율을 낮추었습니다: 기준별 (per-criterion) 모드에서는 10.7%에서 9.5%로, 배치 (batch) 모드에서는 15.6%에서 14.2%로 감소했습니다.
데이터를 위해 트레이스를 마이닝 (mining traces)하고 프롬프팅을 통해 동작의 타겟 증류 (targeted distillation)를 수행하는 것은 검증기와 에이전트 전반을 개선하는 데 있어 계속해서 효과적인 전략입니다.
법률 도메인을 위한 더 나은 에이전트 및 더 효율적인 검증 시스템 구축
검증기(Verifiers)는 세계적인 수준의 법률 에이전트를 구축하기 위한 퍼즐의 한 조각입니다. 오픈 모델(Open model) 검증기는 팀이 평가(Evals)를 수행하고 강화학습(RL) 사후 학습(Post-training)을 수행할 때 비용 대비 성능(Cost-performance tradeoff)의 이점을 제공하여, 이를 수십 배 더 저렴하게 실행할 수 있게 하며, 애초에 이러한 시도를 가능하게 만드는 경우가 많습니다. 또한 저희는 검증을 배치(Batching) 처리하는 것과 같은 단순한 방법이 상당히 잘 작동하며, 비용을 또 다른 수십 배 수준으로 절감해 준다는 것을 발견했습니다.
오픈 모델은 또한 기업들이 가장 중요한 도메인에 맞춰 맞춤형 검증기(Bespoke verifiers)를 미세 조정(Fine-tune)할 수 있는 기회를 제공합니다. 많은 연구가 최첨단 폐쇄형 모델(Frontier closed models)이 증류(Distill)의 대상이 되는 골드 스탠다드(Gold standard)라고 가정하지만, 본 연구에서는 Opus, GPT-5.5, Sonnet조차 레이블(Labels)의 약 4~5%에서 서로 의견이 일치하지 않는 것으로 나타났습니다. 저희는 이러한 믿음에 더욱 도전하기 위해 더 많은 연구가 필요하다고 느낍니다.
저희는 Harvey와 파트너십을 맺고 대규모 환경에서 더 나은 검증 시스템에 대한 연구를 추진하게 되어 기쁩니다. 향후 연구에서는 검증기를 미세 조정하는 것이 사후 학습(Post-training) 및 대규모 평가(Evals) 실행에 미치는 영향에 대해 연구할 예정입니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기