
루프 엔지니어링의 기술 (The Art of Loop Engineering)
요약
에이전트가 안정적으로 업무를 수행하기 위해 필요한 '루프 엔지니어링'의 개념과 단계별 설계 방법을 설명합니다. 단순한 도구 호출을 넘어 검증 루프를 통해 결과물의 품질을 높이는 구조를 다룹니다.
핵심 포인트
- 에이전트는 모델이 도구를 호출하며 루프를 도는 기본 구조를 가짐
- 검증 루프(Verification loop)를 통해 출력물의 정확성과 일관성을 확보 가능
- 채점자(Grader)를 활용하여 기준 미달 시 피드백을 재전송하는 패턴 권장
- LangChain의 프리미티브를 사용하여 루프 스택을 구현할 수 있음
에이전트(Agents)는 현실 세계에서 행동을 취함으로써 업무를 자동화하도록 도와주기 때문에 유용합니다. 하지만 에이전트가 가치 있는 업무를 안정적으로 수행하게 하려면 단순히 좋은 모델만으로는 부족합니다. 설정된 작업 세트에 적합하도록 세심하게 설계된 하네스(harness)가 필요합니다.
핵심 에이전트 알고리즘은 간단합니다. LLM(대규모 언어 모델)에 컨텍스트(context)를 제공하고, 작업이 완료될 때까지 루프(loop) 내에서 도구(tools)를 호출하도록 하는 것입니다. 이것이 가장 기본적인 루프입니다. 하지만 이것이 에이전트를 구동하는 유일한 루프는 아닙니다. Swyx는 최근 "loopcraft: 루프를 쌓는 기술 (the art of stacking loops)"에 관한 훌륭한 글을 썼는데, 이는 더 효과적인 에이전트를 구축하기 위해 루프를 쌓고 확장할 수 있다는 아이디어입니다.
우리는 이 스택(stack)을 어떻게 생각하는지, 그리고 LangChain의 프리미티브(primitives)를 사용하여 각 레벨을 어떻게 구현(instrument)하는지에 대해 설명하겠습니다.
루프 1: 에이전트 (The Agent)
핵심적으로 에이전트는 작업이 완료될 때까지 루프 내에서 도구를 호출하는 모델일 뿐입니다.
.png)
이것이 LangChain의 create_agent가 제공하는 것입니다. 어떤 모델이든 선택하고 도구를 연결하면 작동하는 에이전트 루프를 가질 수 있습니다. 도구는 에이전트에게 현실 세계에서 행동을 취할 수 있는 힘을 부여하는 요소입니다.
우리의 내부 문서 에이전트(이 블로그의 나머지 부분을 위한 동기 부여 예시로 사용될 것입니다)를 예로 들어보겠습니다. 첫 번째 루프 레벨에서, 에이전트는 문서 개선 요청을 받고, 모델은 계획을 세우고 변경 사항을 초안하며, 리포지토리(repos)를 클론하고, 파일을 읽고, 문서를 작성하고, 풀 리퀘스트(pull request)를 여는 등의 작업을 위해 도구를 사용합니다.
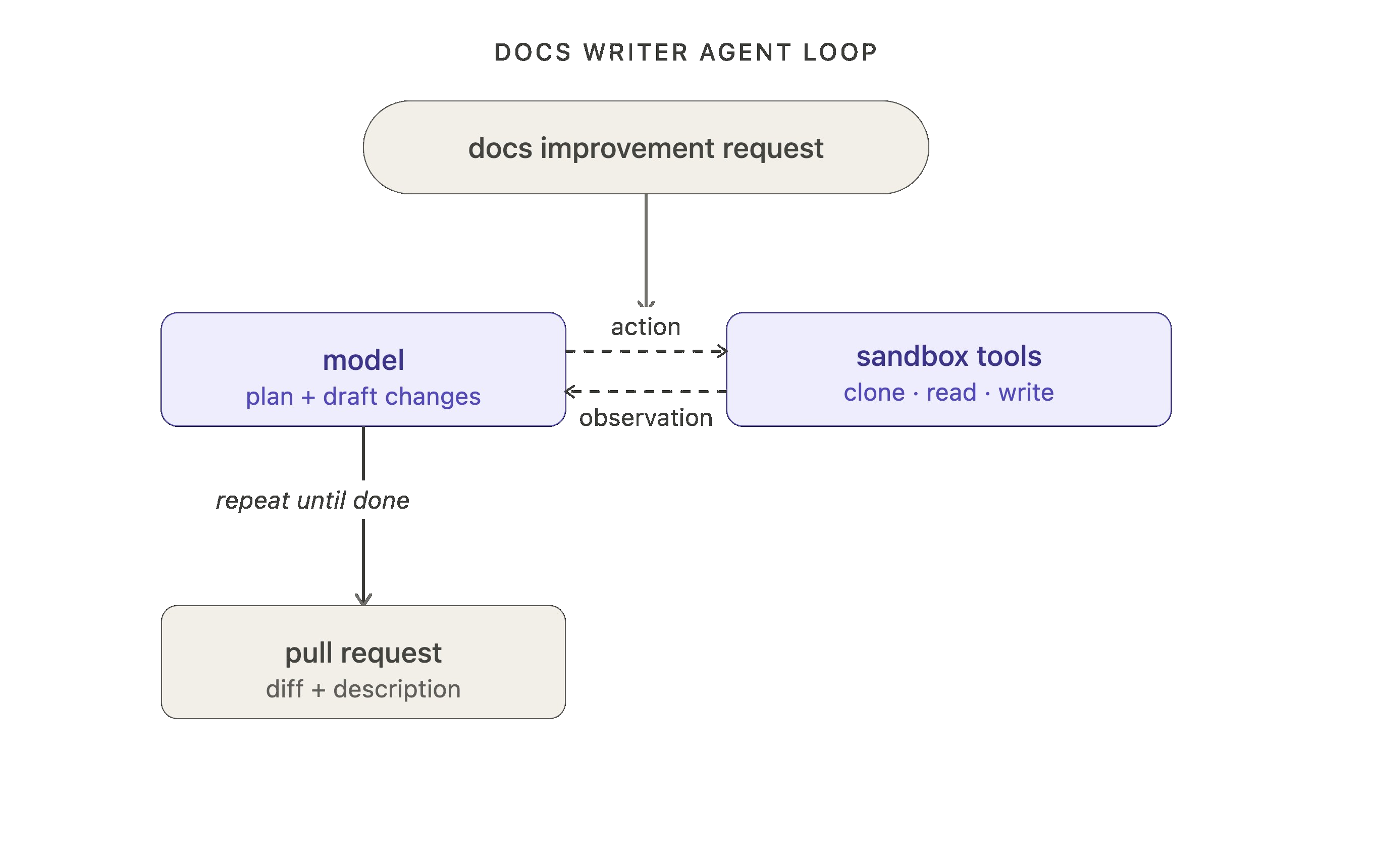
레벨 2: 검증 루프 (Verification loop)
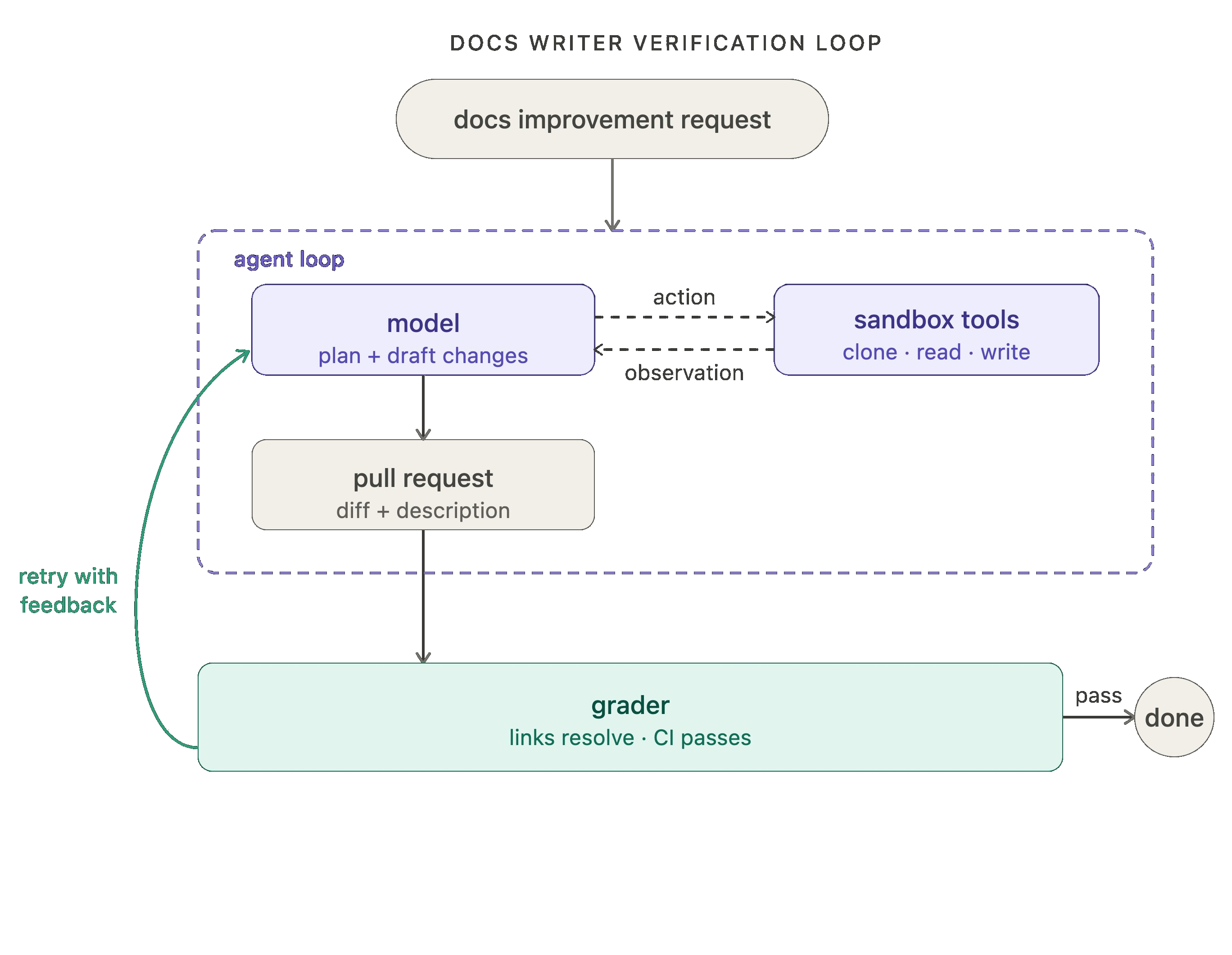
에이전트 루프는 작업을 수행하지만, 첫 번째 시도에서 항상 정확하거나 일관된 결과물을 만들어내지는 않습니다. 일관성이 중요할 때는, 출력을 확인하고 기준에 미달할 경우 모델에 피드백을 다시 보내는 검증 루프(verification loop)로 에이전트를 감싸는 것이 유용할 때가 많습니다.
.png)
검증 루프는 채점자(grader)를 추가합니다. 채점자는 루브릭(rubric, 평가 기준)에 따라 에이전트의 출력을 확인하고, 실패할 경우 피드백과 함께 결과를 다시 보냅니다. 채점자는 결정론적(deterministic)일 수도 있고 에이전트 방식(agentic)일 수도 있습니다 (여기서는 LLM as a judge가 전형적인 예시입니다).
RubricMiddleware가 이 패턴을 처리하거나, after_agent를 통해 직접 연결할 수 있습니다.
create_agent에 훅(hook) 걸기
.
우리의 문서 작성자(docs writer) 예시의 경우, 채점기(grader)가 각 시도 후에 테스트를 실행하여 모든 링크가 정상적으로 연결되는지, 모든 CI 체크를 통과하는지, 그리고 차이점(diff)이 실제로 요청된 범위 내로 제한되어 있는지를 확인합니다. 이러한 종류의 오류를 잡아내기 위해 수동 검토를 할 필요가 없습니다.
한 가지 트레이드오프(tradeoff): 검증을 추가하면 실행당 지연 시간(latency)과 비용이 증가합니다. 하지만 속도보다 품질이 더 중요한 경우, 즉 대부분의 프로덕션(production) 사용 사례에서는 그만한 가치가 있습니다.
레벨 3: 이벤트 기반 루프 (Event driven loop)
에이전트 개발에서 가장 중요한 부분 중 하나는 통합 계층(integrations layer)입니다. 즉, 에이전트가 백그라운드에서 실행될 수 있도록 에이전트를 여러분의 생태계(ecosystem)에 연결하는 것입니다.
이벤트 기반 루프는 에이전트를 생태계에 연결합니다. 새로운 문서가 도착하거나, 스케줄이 트리거되거나, 웹훅(webhook)이 도착하는 등의 이벤트가 발생하면 에이전트가 실행됩니다. 에이전트는 수동으로 호출하는 대상이 아니라, 더 큰 시스템 내부에서 지속적으로 실행되는 구성 요소입니다.
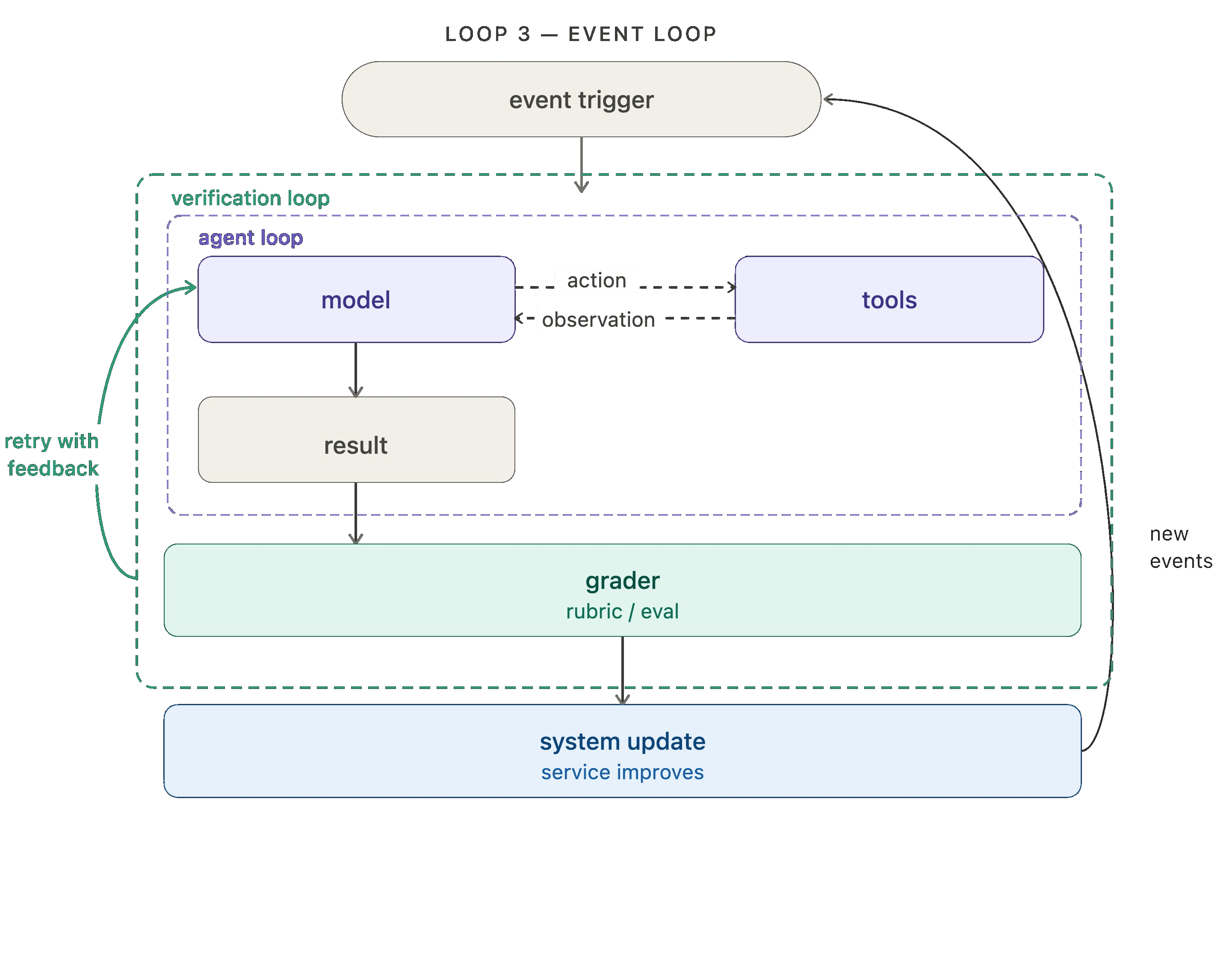
LangSmith Deployment는 cron 스케줄과 웹훅에 대한 지원을 포함하여 트리거 인프라를 지원합니다. cron이 작동하는 인기 있는 사례 중 하나는 openclaw의 "하트비트(heartbeats)"로, 이를 통해 에이전트를 항상 켜져 있는 선제적인(proactive) 어시스턴트로 변모시킵니다.
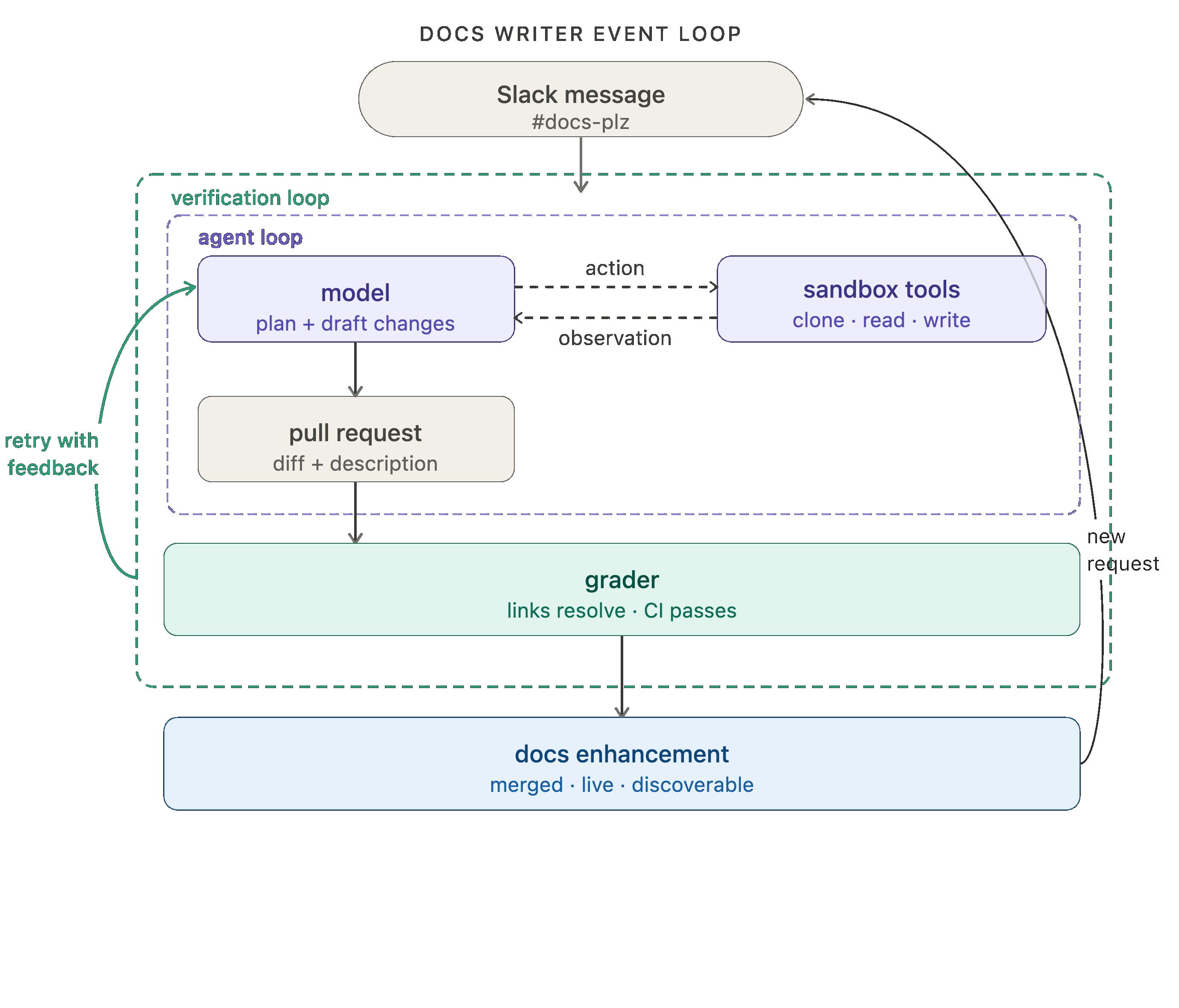
우리의 문서 에이전트는 우리의 노코드(no-code) 에이전트 빌더인 Fleet에 의해 구동됩니다. Fleet의 채널(channels)과 스케줄(schedules)은 이벤트 기반 및 cron 방식의 트리거를 처리합니다. 우리는 #docs-plz Slack 채널에 메시지가 전송될 때마다 문서 에이전트를 실행하기 위해 채널을 사용합니다.
레벨 4: 힐 클라이밍 루프 (Hill climbing loop)
처음 세 가지 루프는 작업을 자동화합니다. 네 번째(그리고 아마도 가장 중요한) 루프는 개선(improvement)을 자동화합니다!
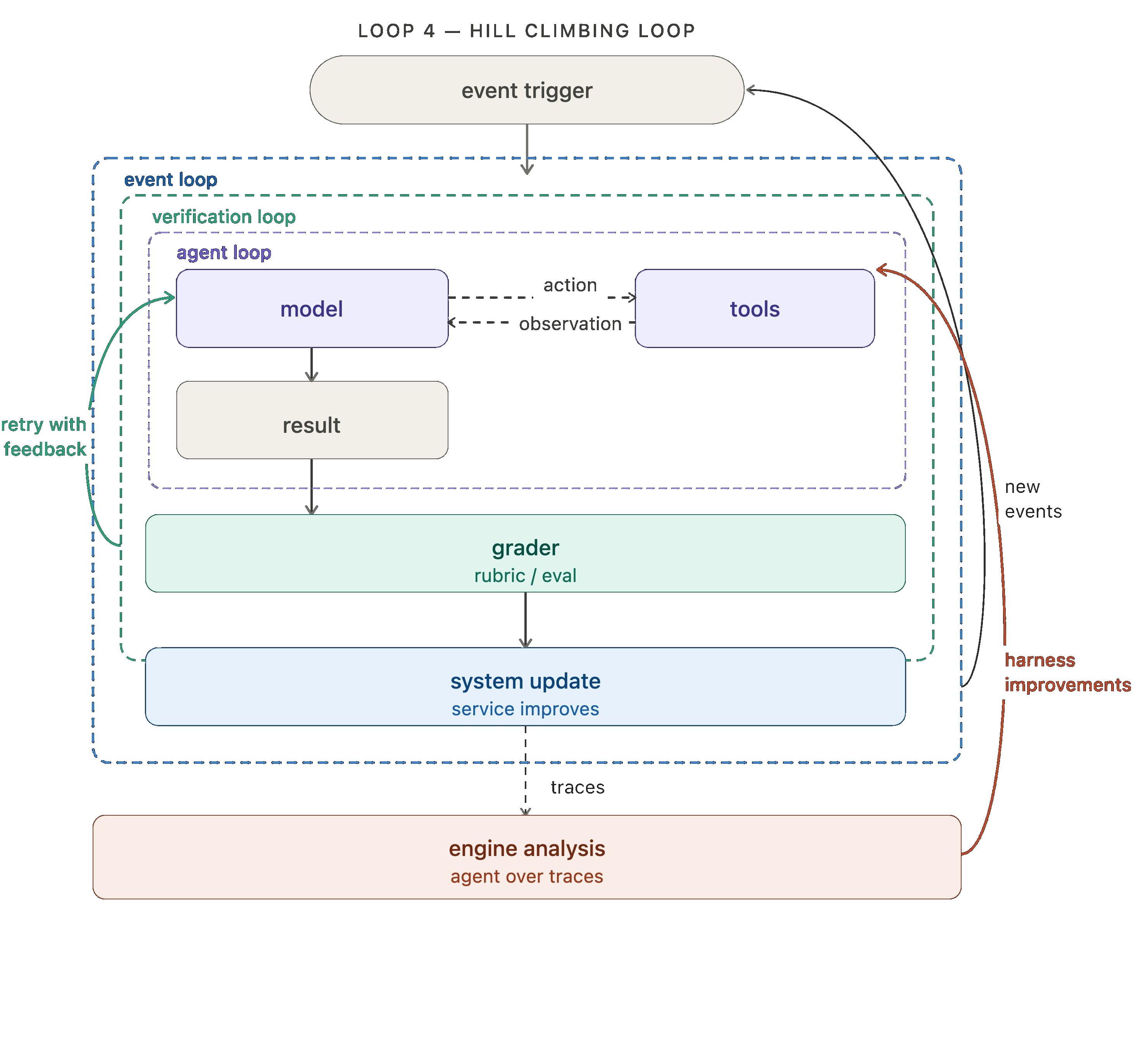
모든 에이전트 실행은 트레이스(trace)를 생성합니다. 즉, 모델이 무엇을 했는지, 어떤 도구(tools)를 호출했는지, 채점기 피드백(grader feedback) 등은 무엇인지에 대한 기록입니다. 이러한 트레이스에는 무엇이 잘 작동하고 무엇이 그렇지 않은지에 대한 가치 높은 신호(signal)가 포함되어 있습니다. 힐 클라이밍 루프는 이러한 트레이스에 대해 분석 에이전트(analysis agent)를 실행하고, 그 결과물을 사용하여 개선된 설정으로 하네스(harness)를 다시 작성합니다. 여기에는 프롬프트/도구 미세 조정(tweaks)이나 채점기 미세 조정이 포함될 수 있습니다.
LangSmith에서는 우리의 트레이스 분석(trace analysis) 에이전트인 Engine을 사용하여 이 네 번째 루프를 계측(instrument)할 수 있습니다.
문서 에이전트(docs agent) 비유를 마무리하자면, 우리는 문서 에이전트의 트레이스(traces)에 대해 Engine을 실행하여 문제를 감지합니다. 여러 트레이스가 잠재적인 문제를 신호하면, 문제가 되는 프롬프트(prompt)나 도구(tool)의 수정을 요청하는 이슈(issue)가 생성됩니다.
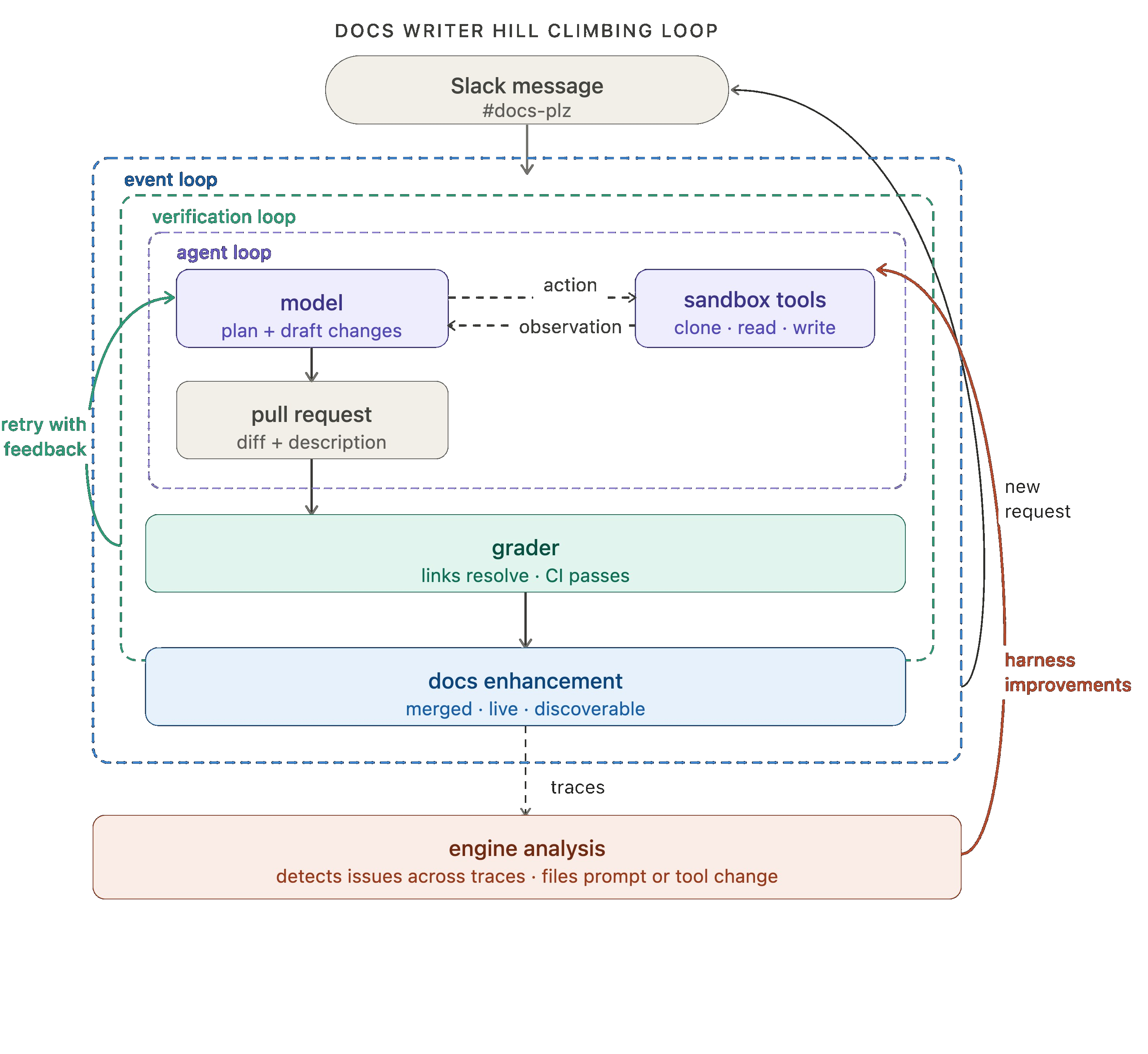
여기서 핵심적인 움직임은 되돌아가는 화살표가 단순히 맨 위로 루프를 돌리는 것이 아니라, 내부로 침투하여 에이전트 루프(agent loop)를 직접 업데이트한다는 점입니다. 외부 루프의 각 사이클은 내부 루프를 더욱 효과적으로 만듭니다.
향후 전망: 프롬프트(prompt)와 도구(tool) 설정은 개선하기 가장 간단한 요소들이지만, 이것이 유일한 옵션은 아닙니다. 오픈 웨이트 모델(open-weight models)을 실행하는 팀의 경우, 트레이스(trace)나 평가(eval) 결과를 학습 신호로 사용하여 모델 자체를 개선하는 강화학습(RL) 미세 조정(fine-tuning)으로 힐 클라이밍(hill climbing) 루프를 연결할 수 있습니다. 메모리(memory)나 검색된 기술(retrieved skills)과 같은 보조 컨텍스트(auxiliary context)도 같은 방식으로 개선될 수 있습니다. 루프는 패턴이며, 무엇을 최적화할지는 여러분에게 달려 있습니다.
인간의 감독과 전문성
자동화가 루프에서 인간을 제거한다는 의미는 아닙니다. 모든 단계에는 인간의 감독이 가치를 더하는 자연스러운 지점들이 존재합니다. 자동 채점기(automated grader)는 링크가 제대로 연결되는지 확인할 수 있지만, 프레임(framing)이 대상 독자에게 적절하지 않다는 것을 알아차리는 데는 인간이 필요합니다. 문맥, 경험, 그리고 안목을 통해 얻은 그러한 판단력이야말로 인간의 검토(human review)가 제 자리를 차지하는 바로 그 지점입니다.
일부 전문 지식은 프롬프트/도구 자체에 코드화되어야 하지만, 민감한 작업(금융 거래, DB 작업 등)의 경우에는 실시간 인간 검토가 필수적입니다. LangChain은 모든 루프에서 이러한 접점들을 쉽게 계측(instrument)할 수 있도록 지원합니다:
- 에이전트 루프(agent loop)에서, 민감한 작업/도구 호출 전에 인간의 입력을 요구합니다.
- 검증 루프(verification loop)에서, 인간이 민감한 워크플로우의 채점자(grader) 역할을 수행할 수 있습니다.
- 애플리케이션 루프(application loop)에서, 인간이 최종 사용자에게 반환되기 전에 출력을 승인할 수 있습니다.
- 힐 클라이밍(hill climbing) 루프에서, 하네스(harness) 개선 사항은 배포 전에 인간의 검토를 거칠 수 있습니다.
LangChain의 모든 오픈 소스 프레임워크는 "인간 참여 (human in the loop)"를 일급 시민 프리미티브 (first class primitive)로 제공합니다.
모든 것을 종합하여
만약 더 표 형식의 뷰를 선호하신다면, 이 네 가지 루프가 어떻게 쌓이는지 다음과 같습니다:
이것이 바로 루프 엔지니어링 (loop engineering) — 또는 swyx가 표현한 대로 루프크래프트 (loopcraft) — 가 실제로 실무에서 구현되는 모습입니다. Steipete, Boris, Andrej와 같은 AI 리더들은 모두 동일한 결론에 도달했습니다: 에이전트 (agents)의 잠재력은 그 주변에 당신이 구축하는 루프 (loops)에 달려 있다는 것입니다.
우리는 한동안 루프 1과 2에 대해 생각해 왔습니다. 하지만 이제는 루프 3과 4로 초점을 전환해야 합니다. 이곳은 당신의 기준에 따라 지속적으로 개선되는 에이전트를 당신의 생태계에 내장함으로써 가치가 복리로 쌓이는 지점입니다.
Satya는 조직적 차원의 이해관계를 다음과 같이 정의합니다: 인간의 판단 (human judgment)과 토큰 자본 (token capital)이 함께 복리로 쌓이는 학습 루프 (learning loops)를 조기에 구축하는 기업은 복제하기 어려운 우위를 점하게 될 것입니다.
감사의 글
심도 있는 검토를 해주신 Vivek, Mason, Harrison, Hunter에게 감사드립니다.
참고 문헌
- deepagents quickstart
- create_agent docs
- rubric middleware
- cron jobs, webhooks
- langsmith engine
- fleet channels
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기