대규모 언어 모델(LLM)의 밑바닥 원리를 배우고 싶다면: train-llm-from-scratch 프로젝트
요약
PyTorch를 사용하여 Transformer 모델을 밑바닥부터 직접 구현하고 학습시키는 실전 튜토리얼 프로젝트를 소개합니다. 단일 GPU나 Colab 환경에서도 실행 가능한 모델 구성 방안을 제공하여 LLM의 작동 원리를 깊이 있게 이해하도록 돕습니다.
핵심 포인트
- PyTorch 기반 Transformer 아키텍처 구현 가이드
- Attention 및 MLP 모듈의 상세 코드와 원리 제공
- 1,300만~20억 파라미터 규모의 모델 학습 지원
- Colab 환경에서 실행 가능한 저사양 최적화 구성
- Pile 오픈 소스 데이터셋을 활용한 실습
대규모 언어 모델 (LLM)의 밑바닥 원리를 배우고 싶지만, 인터넷상의 튜토리얼은 순수하게 이론만 설명하거나, 아니면 바로 오픈 소스 모델을 던져주며 미세 조정 (Fine-tuning)을 시키는 경우가 많습니다. 실제로 처음부터 직접 코드를 작성하며 학습시키는 실전 튜토리얼은 너무 적습니다.
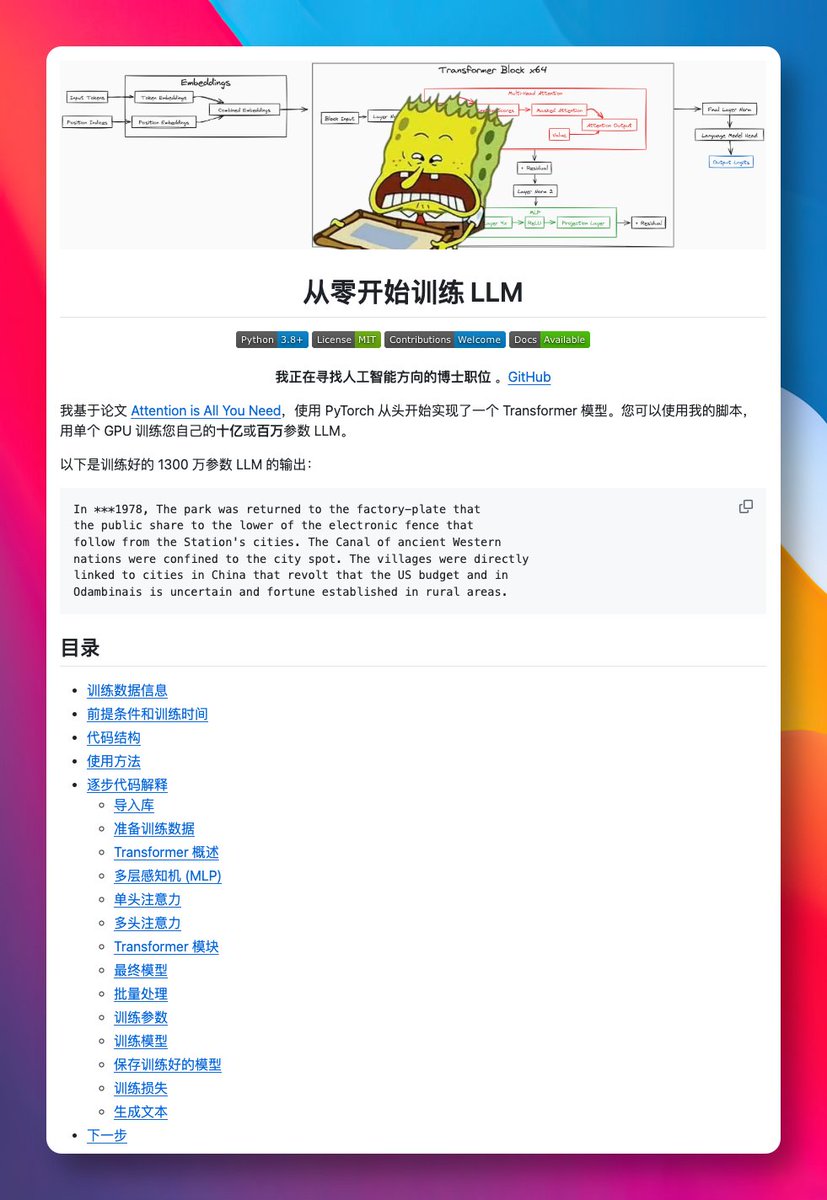
우연히 train-llm-from-scratch 프로젝트를 발견했는데, PyTorch를 사용하여 Transformer 모델을 처음부터 구현하는 방법을 차근차근 가르쳐 주며, 단 한 장의 그래픽 카드 (GPU)로도 학습을 완료할 수 있습니다.
어텐션 메커니즘 (Attention Mechanism), 다층 퍼셉트론 (MLP)부터 완전한 Transformer 아키텍처에 이르기까지, 각 모듈에는 상세한 코드와 원리 도해가 포함되어 있어 따라 하기만 하면 사람의 말을 할 수 있는 언어 모델을 학습시킬 수 있습니다.
GitHub:
http://github.com/FareedKhan-dev/train-llm-from-scratch
...
이 프로젝트는 1,300만 개와 20억 개의 두 가지 파라미터 (Parameter) 규모 구성 방안을 제공합니다. 1,300만 파라미터 모델은 무료 Colab에서도 실행할 수 있으며, 하루 동안 학습시키면 결과를 확인할 수 있습니다.
학습 데이터로는 도서, 논문, 코드 등 다양한 출처를 포함하는 Pile 오픈 소스 데이터셋을 사용합니다.
단순히 API를 호출하는 단계에 머물지 않고 대규모 모델이 어떻게 작동하는지 제대로 이해하고 싶다면, 이 튜토리얼을 따라 직접 실습해 볼 가치가 있습니다.
기술 서적을 한 권 사서 주의 깊게 한 번 다 읽었지만, 몇 달 후 특정 지식 포인트를 찾아보려 했을 때 한참을 헤매도 찾을 수 없었던 적이 있습니다.
그러다 book-to-skill이라는 도구를 발견했는데, 이는 책을 직접 변환해 줍니다
AI 자동 생성 콘텐츠
본 콘텐츠는 X @github_daily (자동 발견)의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기