당신의 하네스, 당신의 메모리
요약
에이전트 시스템 구축의 핵심 요소인 '에이전트 하네스'와 '메모리'의 밀접한 결합 관계를 설명합니다. 하네스는 단순한 스캐폴딩을 넘어 컨텍스트와 메모리를 관리하는 핵심 역량이며, 독점적 API 기반의 폐쇄형 하네스를 사용할 경우 메모리에 대한 통제권을 상실할 위험이 있음을 경고합니다.
핵심 포인트
- 에이전트 하네스는 모델의 발전과 상관없이 도구 및 데이터와의 상호작용을 위해 지속적으로 존재할 필수 요소입니다.
- 메모리는 하네스에 별도로 연결하는 플러그인이 아니라, 하네스의 핵심 기능이자 컨텍스트 관리의 일부입니다.
- 독점적 API를 사용하는 폐쇄형 하네스는 에이전트 메모리에 대한 데이터 소유권과 통제권을 제3자에게 양도하는 결과를 초래합니다.
- Claude Code의 사례처럼 고성능 에이전트를 구현하기 위해서는 막대한 양의 하네스 코드가 필요합니다.
에이전트 하네스 (Agent harnesses)는 에이전트를 구축하는 지배적인 방식이 되고 있으며, 앞으로도 사라지지 않을 것입니다. 이러한 하네스는 에이전트 메모리 (agent memory)와 밀접하게 연결되어 있습니다. 만약 폐쇄형 하네스, 특히 독점적인 API 뒤에 있는 하네스를 사용한다면, 당신은 에이전트 메모리에 대한 통제권을 제3자에게 양도하는 것을 선택하는 것입니다. 메모리는 훌륭하고 지속적인 에이전트 경험 (agentic experiences)을 만드는 데 믿을 수 없을 정도로 중요합니다. 이는 엄청난 락인 (lock in) 효과를 만들어냅니다. 메모리, 그리고 따라서 하네스는 당신이 자신의 메모리를 소유할 수 있도록 개방되어야 합니다.
에이전트 하네스는 에이전트를 구축하는 방식이며, 사라지지 않을 것입니다
에이전트 시스템 (agentic systems)을 구축하는 "최선"의 방법은 지난 3년 동안 극적으로 변했습니다. ChatGPT가 출시되었을 때, 당신이 할 수 있었던 것은 단순한 RAG 체인 (LangChain)뿐이었습니다. 그 후 모델들이 조금 더 좋아지면서 더 복잡한 흐름을 생성할 수 있게 되었습니다 (LangGraph). 그 후 모델들이 훨씬 더 좋아졌고, 이는 새로운 유형의 스캐폴딩 (scaffolding)인 **에이전트 하네스 (agent harnesses)**의 등장으로 이어졌습니다.
에이전트 하네스의 예로는 Claude Code, Deep Agents, Pi (OpenClaw를 구동), OpenCode, Codex, Letta Code 등이 있습니다.
에이전트 하네스는 사라지지 않습니다.
때때로 모델이 스캐폴딩의 점점 더 많은 부분을 흡수할 것이라는 정서가 있습니다. 이는 사실이 아닙니다. 일어났던 일(그리고 앞으로도 계속될 일)은 2023년에 필요했던 많은 스캐폴딩이 더 이상 필요하지 않게 되었다는 것입니다. 하지만 이는 다른 유형의 스캐폴딩으로 대체되었습니다. 에이전트는 정의상 도구 및 기타 데이터 소스와 상호작용하는 LLM입니다. 그러한 유형의 상호작용을 촉진하기 위한 시스템이 LLM 주변에는 항상 존재할 것입니다. 증거가 필요하신가요? Claude Code의 소스 코드가 유출되었을 때, 거기에는 512k 줄의 코드가 있었습니다. 그 코드가 바로 하네스입니다. 세계 최고의 모델을 만드는 사람들조차 하네스에 막대한 투자를 하고 있습니다.
웹 검색과 같은 기능이 OpenAI 및 Anthropic의 API에 내장될 때, 그것들은 "모델의 일부"가 아닙니다. 오히려 그것들은 API 뒤에 위치하며, (도구 호출 (tool calling) 외에는 다른 방법 없이) 해당 웹 검색 API와 모델을 오케스트레이션 (orchestrate) 하는 경량 하네스 (harness)의 일부입니다.
하네스는 메모리와 결합되어 있습니다
Sarah Wooders는 왜 "메모리는 플러그인이 아니라 (하네스이다)"인지에 대해 훌륭한 블로그 글을 작성했으며, 저는 그 의견에 전적으로 동의합니다.
때때로 메모리가 특정 하네스와 분리된 독립적인 서비스라는 정서가 존재합니다. 하지만 현시점에서는 그렇지 않습니다.
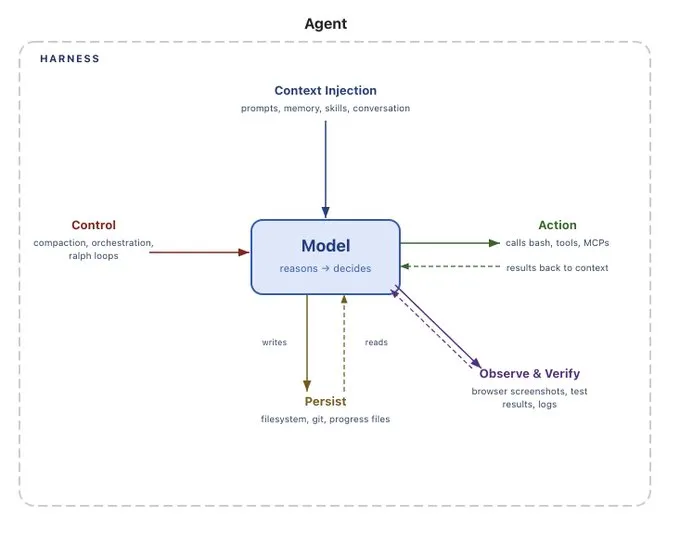
하네스의 큰 책임 중 하나는 컨텍스트 (context)와 상호작용하는 것입니다. Sarah가 표현했듯이:
에이전트 하네스에 메모리를 플러그인처럼 꽂아달라고 요청하는 것은, 자동차에 운전을 플러그인처럼 꽂아달라고 요청하는 것과 같습니다. 컨텍스트를 관리하는 것, 따라서 메모리를 관리하는 것은 에이전트 하네스의 핵심 역량이자 책임입니다.
메모리는 단지 컨텍스트의 한 형태일 뿐입니다. 단기 메모리 (대화 중의 메시지, 대규모 도구 호출 결과)는 하네스에 의해 처리됩니다. 장기 메모리 (세션 간 메모리)는 하네스에 의해 업데이트되고 읽혀야 합니다. Sarah는 하네스가 메모리와 결합되는 다른 많은 방식들을 나열했습니다:
- AGENTS.md 또는 CLAUDE.md 파일이 어떻게 컨텍스트로 로드되는가?
- 기술 메타데이터 (skill metadata)가 에이전트에게 어떻게 보여지는가? (시스템 프롬프트 (system prompt) 내에서? 아니면 시스템 메시지 (system messages) 내에서?)
- 에이전트가 자신의 시스템 지침 (system instructions)을 수정할 수 있는가?
- 압축 (compaction) 과정에서 무엇이 살아남고, 무엇이 손실되는가?
- 상호작용이 저장되고 쿼리 가능 (queryable)하게 만들어지는가?
- 메모리 메타데이터가 에이전트에게 어떻게 제시되는가?
- 현재 작업 디렉토리 (working directory)는 어떻게 표현되는가? 파일 시스템 정보는 얼마나 노출되는가?
현재 메모리(memory)라는 개념은 초기 단계에 있습니다. 메모리는 아직 매우 초기 단계입니다. 투명하게 말하자면, 장기 메모리(long term memory)는 종종 MVP(Minimum Viable Product, 최소 기능 제품)의 일부가 아닙니다. 먼저 에이전트(agent)가 전반적으로 작동하게 만든 다음, 개인화(personalization)를 고민할 수 있습니다. 이는 우리(업계 전체로서)가 여전히 메모리를 파악해 나가는 중임을 의미합니다. 즉, 메모리에 대한 잘 알려진 또는 공통된 추상화(abstractions)가 없다는 뜻입니다. 만약 메모리가 더 알려지게 되고 모범 사례(best practices)를 발견하게 된다면, 별도의 메모리 시스템을 구축하는 것이 타당해질 수도 있습니다. 하지만 현 시점에서는 아닙니다. 지금은 Sarah가 말했듯이, "궁극적으로 하네스(harness)가 컨텍스트(context)와 상태(state)를 전반적으로 어떻게 관리하느냐가 에이전트 메모리의 토대가 됩니다."
하네스를 소유하지 못한다면, 당신의 메모리도 소유할 수 없습니다
하네스는 메모리와 밀접하게 연결되어 있습니다.
만약 폐쇄형 하네스(closed harness)를 사용한다면, 특히 그것이 API 뒤에 숨겨져 있다면, 당신은 당신의 메모리를 소유할 수 없습니다.
이는 여러 가지 방식으로 나타납니다.
약간 나쁜 경우: 만약 당신이 상태 유지 API(stateful API, 예: OpenAI의 Responses API 또는 Anthropic의 서버 측 압축(server side compaction))를 사용한다면, 당신은 그들의 서버에 상태를 저장하고 있는 것입니다. 만약 모델을 교체하고 이전 스레드(threads)를 재개하고 싶다면, 그것은 더 이상 불가능합니다.
나쁜 경우: 만약 당신이 폐쇄형 하네스(내부적으로 오픈 소스가 아닌 Claude Code를 사용하는 Claude Agent SDK와 같은 경우)를 사용한다면, 이 하네스는 당신이 알 수 없는 방식으로 메모리와 상호작용합니다. 아마도 클라이언트 측에서 일부 아티팩트(artifacts)를 생성할 수도 있겠지만, 그것의 형태는 어떠하며 하네스가 그것들을 어떻게 사용해야 할까요? 그것은 알 수 없는 영역이며, 따라서 한 하네스에서 다른 하네스로 이전(transferrable)할 수 없습니다.
하지만 가장 최악은 다른 것입니다 - 장기 메모리를 포함한 하네스 전체가 API 뒤에 있는 경우입니다.
이 상황에서는 장기 메모리를 포함하여 메모리에 대한 소유권이나 가시성(visibility)이 전혀 없습니다. 당신은 하네스를 알지 못하며(이는 메모리를 어떻게 사용하는지도 모른다는 것을 의미합니다), 더 심각한 것은 메모리 자체를 소유하지도 못한다는 것입니다! 일부 부분은 API를 통해 노출될 수도 있고, 전혀 노출되지 않을 수도 있지만, 당신은 그것을 제어할 수 없습니다.
사람들이 “모델이 하네스 (harness)의 더 많은 부분을 흡수할 것이다”라고 말할 때, 그들이 실제로 의미하는 바는 바로 이것입니다. 즉, 이러한 메모리 (memory) 관련 부분들이 모델 제공업체들이 제공하는 API 뒤로 숨겨지게 될 것이라는 뜻입니다.
이것은 믿기 힘들 정도로 경고할 만한 일입니다. 이는 메모리가 단일 플랫폼, 단일 모델에 종속(lock-in)될 것임을 의미하기 때문입니다.
모델 제공업체들은 이렇게 할 강력한 동기를 가지고 있습니다. 그리고 그들은 이미 시작했습니다. Anthropic은 Claude Managed Agents를 출시했습니다. 이는 말 그대로 모든 것을 API 뒤로 배치하여 그들의 플랫폼에 종속시킵니다.
하네스 전체가 API 뒤로 숨지 않더라도, 모델 제공업체들은 점점 더 많은 부분을 API 뒤로 옮기려는 유인을 가지며, 이미 그렇게 하고 있습니다. 예를 들어, Codex는 오픈 소스임에도 불구하고 (OpenAI 생태계 외부에서는 사용할 수 없는) 암호화된 압축 요약본 (compaction summary)을 생성합니다.
그들은 왜 이렇게 하는 것일까요? 메모리는 중요하며, 모델만으로는 얻을 수 없는 종속성 (lock-in)을 만들어내기 때문입니다.
메모리는 중요하며, 종속성을 만들어냅니다
메모리는 아직 초기 단계이지만, 그것이 중요하다는 점은 모두에게 명확합니다. 메모리는 사용자가 에이전트 (agent)와 상호작용함에 따라 에이전트가 더 나아지게 만들고, 데이터 플라이휠 (data flywheel)을 구축할 수 있게 해줍니다. 또한 당신의 에이전트가 각 사용자에게 개인화될 수 있도록 하며, 사용자의 욕구와 사용 패턴에 맞춰 형성되는 에이전트적 경험 (agentic experience)을 구축할 수 있게 합니다.
메모리가 없다면, 당신의 에이전트는 동일한 도구에 접근할 수 있는 누구에 의해서도 쉽게 복제될 수 있습니다.
메모리가 있다면, 당신은 사용자 상호작용과 선호도가 담긴 독점적인 데이터셋 (proprietary dataset)을 구축하게 됩니다. 이 독점적 데이터셋을 통해 당신은 차별화되고 점점 더 지능적인 경험을 제공할 수 있습니다.
지금까지 모델 제공업체를 전환하는 것은 비교적 쉬웠습니다. 그들은 거의 동일하거나 매우 유사한 API를 가지고 있기 때문입니다. 물론 프롬프트 (prompt)를 약간 수정해야 하겠지만, 그것은 그리 어려운 일이 아닙니다.
하지만 이것은 모두 그들이 상태 비저장 (stateless) 방식이기 때문에 가능한 것입니다.
어떠한 상태 (state)라도 연관되는 순간, 전환은 훨씬 더 어려워집니다. 왜냐하면 이 메모리가 중요하기 때문입니다. 그리고 만약 당신이 전환한다면, 그 메모리에 대한 접근 권한을 잃게 됩니다.
이야기를 하나 해보겠습니다. 저에게는 내부적으로 사용하는 이메일 어시스턴트가 있습니다. 이것은 기업용 OpenClaws를 구축하기 위한 우리의 노코드 (no-code) 플랫폼인 Fleet의 템플릿을 기반으로 구축되었습니다. 이 플랫폼에는 메모리 (memory)가 내장되어 있어서, 지난 몇 달 동안 제가 이메일 어시스턴트와 상호작용하면서 메모리가 쌓여왔습니다. 그런데 몇 주 전, 제 에이전트 (agent)가 실수로 삭제되었습니다. 정말 화가 났습니다! 동일한 템플릿으로 에이전트를 다시 만들려고 시도했지만, 경험은 훨씬 더 나빴습니다. 저의 모든 선호도, 말투, 그 모든 것을 다시 가르쳐야 했습니다.
제 이메일 에이전트가 삭제된 것의 긍정적인 측면은, 메모리가 얼마나 강력하고 고착성 (sticky)이 있을 수 있는지를 깨닫게 해주었다는 점입니다.
오픈 메모리, 오픈 하네스 (Open Memory, Open Harnesses)
메모리는 개방되어야 하며, 에이전트 경험 (agentic experience)을 개발하는 누구의 소유든 되어야 합니다. 이를 통해 당신이 실제로 제어할 수 있는 독점적인 데이터셋 (proprietary dataset)을 구축할 수 있습니다.
메모리(그리고 따라서 하네스 (harnesses))는 모델 제공자 (model providers)로부터 분리되어야 합니다. 당신은 당신의 유스케이스 (use case)에 가장 적합한 어떤 모델이든 시도해 볼 수 있는 선택권 (optionality)을 가져야 합니다. 모델 제공자들은 메모리를 통해 락인 (lock-in)을 유도하도록 인센티브를 받습니다.
이것이 바로 우리가 Deep Agents를 구축하고 있는 이유입니다. Deep Agents는:
- 오픈 소스 (open source)입니다.
- 모델 불가지론적 (model agnostic)입니다.
- agents.md 및 skills와 같은 오픈 표준을 사용합니다. 메모리 저장을 위해 Mongo, Postgres, Redis 및 기타 데이터베이스를 위한 플러그인을 갖추고 있습니다.
- LangSmith Deployment를 통해 배포 가능합니다.
- 셀프 호스팅 (self-hostable)이 가능하며, 어떤 클라우드에서도 배포할 수 있습니다.
- 메모리 저장소로 사용할 자신만의 데이터베이스를 가져올 수 있습니다.
- 모든 표준 웹 호스팅 프레임워크 뒤에서 작동합니다.
당신의 메모리를 소유하기 위해서는, 오픈 하네스 (Open Harness)를 사용해야 합니다.
지금 바로 Deep Agents를 사용해 보세요.
검토와 의견을 주신 몇 분께 감사드립니다:
*Deep Agents와 메모리에 관한 훌륭한 작업을 많이 수행하고 있는 Sydney Runkle
*에이전트 하네스 (agent harnesses)에 관한 선도적인 목소리를 내고 있는 Viv Trivedy
*금융 에이전트를 위한 컨텍스트 엔지니어링 (context engineering)에 관한 멋진 글을 쓴 Nuno Campos
상태 유지 에이전트 (stateful agents)의 최전선에 지속적으로 서 있는 기업인 Letta의 CTO Sarah Wooders
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기