관측성(Observability)을 통한 AI 에이전트 디버깅 및 평가 방법 — LangChain 가이드
요약
AI 에이전트는 전통적인 소프트웨어와 달리 비결정론적이며 복잡한 추론 과정을 거치므로, 기존의 코드 기반 디버깅과는 다른 관측성(Observability) 접근 방식이 필요합니다. 에이전트의 행동을 기록하는 트레이스(Traces)를 통해 추론 과정을 추적하고, 이를 바탕으로 체계적인 평가를 수행하는 것이 에이전트 엔지니어링의 핵심입니다.
핵심 포인트
- 에이전트의 진실의 근원(Source of truth)은 코드가 아닌 실행 시 발생하는 트레이스(Traces)로 이동함
- 전통적인 소프트웨어 관측성과 달리 에이전트는 불확실성과 복잡한 루프를 포함하는 추론 디버깅이 필수적임
- 트레이싱은 에이전트의 행동이 발생하는 지점을 기록하여 다양한 방식의 평가를 지원함
- 에이전트 엔지니어링은 트레이싱과 평가를 통한 반복적인 개선 루프를 통해 완성됨
핵심 요약 (Key Takeaways)
에이전트가 어떻게 추론(Reasoning)하는지 이해하지 못하면 신뢰할 수 있는 에이전트를 구축할 수 없으며, 체계적인 평가(Evaluation) 없이는 개선 사항을 검증할 수 없습니다. 이 글에서는 에이전트 관측성(Agent Observability)을 위한 기본 요소(Primitives), 다양한 입도(Granularities)에서 에이전트를 평가하는 방법, 그리고 프로덕션 트레이스(Production Traces)가 어떻게 지속적인 개선의 토대가 되는지 설명합니다.
요약 (TL;DR)
- 에이전트를 실제로 실행해 보기 전까지는 에이전트가 무엇을 할지 알 수 없습니다. 즉, 에이전트 관측성은 소프트웨어 관측성(Software Observability)과는 다르며 더 중요합니다.
- 에이전트는 종종 복잡하고 개방적인(Open-ended) 작업을 수행하므로, 에이전트를 평가하는 것은 소프트웨어를 평가하는 것과 다릅니다.
- 트레이스(Traces)는 에이전트의 행동이 어디에서 발생하는지를 기록하기 때문에, 다양한 방식으로 평가를 지원합니다.
전통적인 소프트웨어에서 문제가 발생하면 무엇을 해야 할지 알 수 있습니다. 에러 로그(Error logs)를 확인하고, 스택 트레이스(Stack trace)를 살펴보고, 실패한 코드 라인을 찾으면 됩니다. 하지만 AI 에이전트는 우리가 디버깅하는 대상을 바꾸어 놓았습니다. 에이전트가 작업을 완료하기 위해 2분 동안 200단계를 거치며 도중에 실수를 저지른다면, 이는 다른 유형의 오류입니다. 실패한 코드가 없기 때문에 스택 트레이스도 존재하지 않습니다. 실패한 것은 에이전트의 추론(Reasoning)입니다.
코드 디버깅에서 추론 디버깅으로
당신은 여전히 어떤 도구(Tools)가 존재하는지, 어떤 데이터가 사용 가능한지 등 에이전트를 정의하기 위해 코드를 작성합니다. 에이전트의 행동을 안내하기 위해 프롬프트(Prompts)와 도구 설명(Tool descriptions)을 작성하지만, 실행해 보기 전까지는 LLM이 이 지침을 어떻게 해석할지 알 수 없습니다. 따라서 진실의 근원(Source of truth)은 코드에서 에이전트가 실제로 무엇을 했는지 보여주는 트레이스(Traces)로 이동합니다.
에이전트 엔지니어링(Agent engineering)은 반복적인 과정이며, 트레이싱(Tracing)과 평가(Evaluation)는 그 루프를 완성하는 방법입니다. 이 포스트에서는 왜 에이전트 관측성과 평가가 전통적인 소프트웨어와 근본적으로 다른지, 어떤 새로운 기본 요소와 관행이 필요한지, 그리고 관측성이 어떻게 평가와 분리될 수 없는 방식으로 평가를 지원하는지 탐구할 것입니다.
에이전트 관측성 ≠ 소프트웨어 관측성
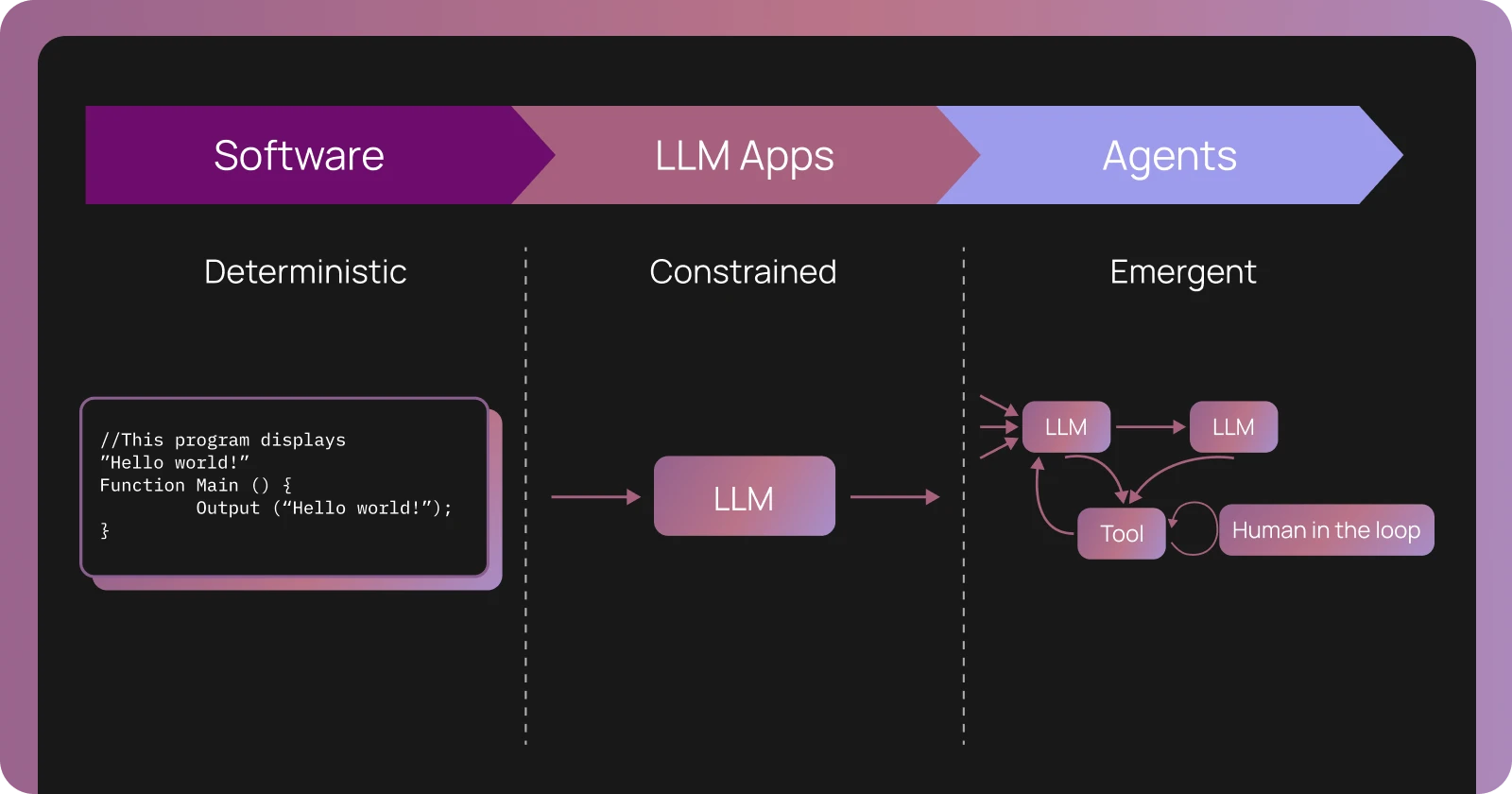
LLM 이전의 소프트웨어는 대체로 결정론적(Deterministic)이었습니다. 동일한 입력이 주어지면 동일한 출력을 얻을 수 있었습니다. 로직은 코드로 명문화되어 있었습니다. 코드를 읽으면 시스템이 정확히 어떻게 동작하는지 알 수 있었습니다. 문제가 발생하면 로그가 어떤 서비스나 함수에서 실패했는지 알려주었고, 그러면 코드로 돌아가 왜 그런 일이 발생했는지 이해하고 수정할 수 있었습니다.
AI 에이전트는 결정론과 코드를 진실의 근원(Source of truth)으로 삼는 가정을 깨뜨립니다. 전통적인 소프트웨어에서 LLM 애플리케이션을 거쳐 에이전트로 이동함에 따라, 각 단계는 더 많은 불확실성을 도입합니다. LLM 애플리케이션은 컨텍스트와 함께 LLM에 단일 호출을 수행하여 자연어 고유의 "모호함(Fuzziness)"을 도입하지만, 여전히 하나의 LLM 호출로 제한됩니다.
하지만 에이전트는 작업이 완료되었다고 판단할 때까지 LLM과 도구(Tools)를 루프(Loop) 내에서 호출하며, 수십 또는 수백 단계에 걸쳐 추론하고, 도구를 호출하며, 상태(State)를 유지하고, 컨텍스트에 따라 동작을 조정할 수 있습니다. 에이전트를 구축할 때, 여러분은 코드와 프롬프트(Prompt)를 통해 애플리케이션 로직을 권장하려고 시도합니다. 하지만 실제로 LLM을 실행하기 전까지는 이 로직이 무엇을 할지 알 수 없습니다.
무언가 잘못되었을 때, 여러분은 실패한 단 한 줄의 코드를 찾는 것이 아닙니다. 대신 다음과 같은 질문을 던지게 됩니다:
- 200단계 중 23단계에서 에이전트는 왜
read_file대신edit_file을 호출하기로 결정했는가? - 어떤 컨텍스트와 프롬프트 지침이 그 결정에 영향을 주었는가? - 이 2분 동안의 200단계 궤적(Trajectory) 중 어느 지점에서 에이전트가 경로를 벗어났는가?
전통적인 트레이싱(Tracing) 도구는 이러한 질문에 답할 수 없습니다. 200단계의 트레이스는 사람이 분석하기에 너무 방대하며, 전통적인 트레이스는 각 결정 뒤에 숨겨진 추론 컨텍스트(Reasoning context)를 포착하지 못합니다. 단지 어떤 서비스가 호출되었고 각 호출에 시간이 얼마나 걸렸는지만을 포착할 뿐입니다.
에이전트 평가 ≠ 소프트웨어 평가
전통적인 소프트웨어 테스트는 결정론적인 단언(Deterministic assertions)에 의존합니다. 즉, output == expected_output을 확인하는 테스트를 작성하고, 통과 여부를 검증한 뒤 배포합니다. 온라인 평가(A/B 테스트, 제품 분석)는 비즈니스 영향을 별도로 측정합니다. 에이전트를 평가하는 것은 몇 가지 핵심적인 측면에서 소프트웨어를 평가하는 것과 다릅니다:
1. 코드 경로가 아닌 추론(Reasoning)을 테스트합니다
전통적인 소프트웨어는 다양한 세분화 수준(단위 테스트(Unit), 통합 테스트(Integration), E2E 테스트)에서 테스트를 수행하며, 읽고 수정할 수 있는 결정론적인(Deterministic) 코드 경로를 테스트합니다. 에이전트 역시 다양한 수준의 테스트가 필요하지만, 더 이상 코드 경로를 테스트하는 것이 아니라 추론(Reasoning)을 테스트하게 됩니다:
단일 단계(Single-step): 에이전트가 이 시점에 올바른 결정을 내렸는가?
전체 턴(Full-turn): 에이전트가 엔드 투 엔드(End-to-end) 실행에서 잘 수행했는가?
멀티 턴(Multi-turn): 에이전트가 대화 전반에 걸쳐 문맥(Context)을 유지했는가?
2. 프로덕션(Production)이 주요 학습 도구가 됩니다
전통적인 소프트웨어에서는 오프라인 테스트(단위 테스트, 통합 테스트, 스테이징 환경)를 통해 대부분의 정확성 문제를 잡아낼 수 있습니다. 카나리 배포(Canary deployments)나 피처 플래그(Feature flags)를 통해 프로덕션 환경에서도 테스트를 수행하지만, 그 목적은 놓친 엣지 케이스(Edge cases)나 통합 문제를 포착하는 데 있습니다.
에이전트의 경우, 프로덕션은 다른 역할을 수행합니다. 모든 자연어 입력은 고유하기 때문에, 사용자가 요청을 어떻게 표현할지 또는 어떤 엣지 케이스가 존재할지 예측할 수 없습니다. 프로덕션 트레이스(Production traces)는 예측할 수 없었던 실패 모드(Failure modes)를 드러내며, 실제 사용자 상호작용에서
Runs: 단일 단계에서 LLM이 수행한 작업 캡처
Run(런)은 단일 실행 단계를 캡처합니다. 이는 특정 시점에 LLM이 어떻게 행동했는지 파악하는 데 가장 유용합니다. 여기에는 모든 지침(Instructions), 사용된 도구(Tools), 컨텍스트(Context)를 포함하여 LLM 호출에 대한 전체 프롬프트(Prompt)가 포함됩니다.
이 Run은 두 가지 목적으로 사용됩니다:
디버깅(Debugging) 용도: 에이전트가 특정 단계에서 정확히 무엇을 생각하고 있었는지 확인합니다. 프롬프트에 무엇이 있었나요? 어떤 도구를 사용할 수 있었나요? 왜 이 동작을 선택했나요?
평가(Evaluation) 용도: 이 Run에 대해 어설션(Assertions)을 작성합니다. 에이전트가 올바른 도구를 호출했나요? 올바른 인자(Arguments)를 사용했나요?
Traces: 궤적(Trajectories) 캡처
Trace(트레이스)는 발생한 모든 Run을 서로 연결하여 에이전트의 전체 실행 과정을 캡처합니다. 추론 트레이스(Reasoning trace)는 다음을 캡처합니다:
- 트레이스를 구성하는 Run으로 캡처된, 각 단계에서 모델로 입력되는 모든 정보
- 인자(Arguments) 및 결과(Results)를 포함한 모든 도구 호출 (Tool calls)
- 단계들이 서로 어떻게 연관되는지 보여주는 중첩 구조 (Nested structure)
에이전트 트레이스는 방대합니다. 일반적인 분산 트레이스(Distributed trace)가 몇 백 바이트 정도라면, 에이전트 트레이스는 이보다 몇 배나 더 클 수 있습니다. 복잡하고 오래 실행되는 에이전트의 경우, 트레이스는 수백 메가바이트에 달할 수 있습니다. 이러한 컨텍스트는 에이전트의 추론을 디버깅하고 평가하는 데 필수적입니다.
Threads: 멀티턴 대화 컨텍스트
단일 트레이스는 하나의 에이전트 실행을 캡처하지만, 에이전트는 종종 사용자 또는 시스템과의 여러 상호작용을 포함하는 **세션(Sessions)**을 통해 작동합니다. Thread(스레드)는 여러 에이전트 실행(트레이스)을 하나의 대화 세션으로 그룹화하여 다음을 보존합니다:
멀티턴 컨텍스트 (Multi-turn context): 사용자 및 에이전트 간의 모든 상호작용을 시간 순서대로 기록
상태 진화 (State evolution): 턴(Turn)이 진행됨에 따라 에이전트의 메모리, 파일 또는 기타 아티팩트(Artifacts)가 어떻게 변했는지 기록
시간 범위 (Time span): 대화는 몇 분, 몇 시간 또는 며칠 동안 지속될 수 있음
10번의 턴(turn) 동안은 잘 작동하다가 11번째 턴에서 갑자기 실수를 하기 시작하는 코딩 에이전트(coding agent)의 디버깅을 가정해 봅시다. 11번째 턴의 트레이스(trace)만 단독으로 본다면 에이전트가 합리적인 도구(tool)를 호출한 것처럼 보일 수 있습니다. 하지만 전체 스레드(thread)를 조사해 보면, 6번째 턴에서 에이전트가 잘못된 가정을 바탕으로 메모리(memory)를 업데이트했으며, 11번째 턴에 이르러 그 잘못된 컨텍스트(context)가 버그가 있는 동작으로 누적되었음을 발견하게 됩니다.
스레드(Threads)는 에이전트의 행동이 시간이 지남에 따라 어떻게 진화하는지, 그리고 상호작용 전반에 걸쳐 컨텍스트(context)가 어떻게 축적(또는 저하)되는지를 이해하는 데 필수적입니다.
이것이 에이전트 평가에 미치는 영향
에이전트의 행동은 런타임(runtime)에만 나타나며, 관측성(observability)(실행(runs), 트레이스(traces), 스레드(threads))을 통해서만 포착됩니다. 이는 행동을 평가하기 위해서는 관측성 데이터(observability data)를 평가해야 함을 의미합니다. 여기서 두 가지 핵심 질문이 제기됩니다.
- 어떤 입도(granularity)로 에이전트를 평가할 것인가? 실행(run), 트레이스(trace), 또는 스레드(thread) 수준 중 어느 단계인가?
- 언제 에이전트를 평가할 것인가? 행동이 에이전트를 실행할 때만 나타난다면, 소프트웨어와 동일한 방식으로 오프라인(offline)에서 에이전트를 평가할 수 있는가?
다양한 입도 수준에서의 에이전트 평가
에이전트는 관측성 기본 요소(observability primitives)와 1:1로 매핑되는 다양한 입도(granularity) 수준에서 평가할 수 있습니다. 무엇을 평가하느냐에 따라 필요한 기본 요소가 결정됩니다.
- 단일 단계 평가 (Single-step evaluation): 개별 실행(runs)을 검증 $\rightarrow$ 에이전트가 특정 단계에서 올바른 결정을 내렸는가?
- 전체 턴 평가 (Full-turn evaluation): 완전한 트레이스(traces)를 검증 $\rightarrow$ 에이전트가 전체 작업을 올바르게 수행했는가?
- 멀티 턴 평가 (Multi-turn evaluation): 스레드(threads)를 검증 $\rightarrow$ 에이전트가 대화 전반에 걸쳐 컨텍스트(context)를 유지했는가?
단일 단계 평가 (Single-step evaluation): 결정을 위한 단위 테스트 (unit tests)
때로는 전체 에이전트를 실행하지 않고 특정 결정 지점(decision point)을 검증해야 할 때가 있습니다. 특정 시나리오에서 에이전트가 올바른 도구(tool)를 선택했는지, 또는 올바른 인자(arguments)를 사용했는지 확인하고 싶을 수 있습니다.
이것은 에이전트 추론 (agent reasoning)을 위한 단위 테스트 (unit test)와 같습니다. 특정 상태 (대화 기록, 사용 가능한 도구, 현재 작업)를 설정하고, 에이전트를 한 단계 (one step) 실행한 뒤, 에이전트가 올바른 결정을 내렸는지 확인 (assert)하는 방식입니다. 단일 단계 평가 (Single-step evaluation)는 실행 (runs), 즉 개별 LLM 호출을 검증합니다.
예시: 캘린더 에이전트의 도구 선택 테스트
일정 관리 에이전트는 일정을 잡기 전에 사용 가능한 회의 시간을 먼저 찾아야 합니다. 에이전트가 즉시 회의를 생성하려고 시도하는 대신, 먼저 가용성을 확인하는지 검증하고 싶을 것입니다.
귀하의 단일 단계 테스트:
- 상태 설정: 대화 기록 = 사용자가 "내일 아침 Harrison과 회의를 잡아줘"라고 말함, 사용 가능한 도구 = [
find_meeting_times,schedule_meeting,send_email] - 한 단계 실행: 에이전트가 다음 동작을 생성함
- 확인 (Assert): 에이전트가
find_meeting_times를 선택함 (schedule_meeting이 아님)
실행 (runs) 데이터가 필요한 이유: 단일 단계 테스트는 종종 오류가 발생하는 실제 운영 (production) 사례에서 비롯됩니다. 이러한 사례를 재현하려면 해당 단계 직전의 에이전트의 정확한 상태가 필요합니다. 상세한 실행 캡처 (run captures)만이 이를 얻을 수 있는 유일한 방법입니다!
단일 단계 평가는 효율적이며 개별 결정 지점에서의 회귀 (regressions)를 잡아냅니다. 실제로 에이전트 테스트 스위트 (test suites)의 약 절반은 전체 에이전트 실행의 오버헤드 없이 특정 추론 동작을 격리하고 검증하기 위해 이러한 단일 단계 테스트를 사용합니다.
2. 전체 턴 평가 (Full-turn evaluation): 엔드 투 엔드 궤적 평가 (end-to-end trajectory assessment)
때로는 에이전트의 전체 실행 과정을 확인해야 할 때가 있습니다. 전체 턴 평가는 트레이스 (traces), 즉 모든 실행 (runs)을 포함한 완전한 에이전트 실행을 검증하며, 다음과 같은 여러 차원을 테스트할 수 있게 해줍니다.
궤적 (Trajectory): 에이전트가 필요한 도구들을 호출했는가? 버그를 수정하는 코딩 에이전트의 경우, 다음과 같이 확인할 수 있습니다: "에이전트는 read_file을 호출한 다음, edit_file을 호출하고, 그 다음 run_tests를 호출했어야 한다." 정확한 순서는 다를 수 있지만, 특정 도구들은 반드시 호출되어야 합니다.
최종 응답 (Final response): 출력 결과가 정확하고 유용했는가? 연구나 코딩과 같은 개방형 작업(open-ended tasks)의 경우, 특정 경로를 거쳤는지보다 최종 답변의 품질이 더 중요할 때가 많습니다.
상태 변화 (State changes): 에이전트가 올바른 아티팩트(artifacts)를 생성했는가? 코딩 에이전트의 경우, 에이전트가 작성한 파일을 검사하여 올바른 코드가 포함되어 있는지 확인해야 합니다. 메모리(memory)가 있는 에이전트의 경우, 올바른 정보를 저장했는지 확인해야 합니다.
에이전트가 사용자의 선호도를 기억하는지 테스트하려면 다음 세 가지 사항을 검증해야 합니다.
- 궤적 (Trajectory): 에이전트가 자신의 메모리 파일에
edit_file을 호출했는가? - 최종 응답 (Final response): 에이전트가 사용자에게 업데이트 사항을 확인해 주었는가?
- 상태 (State): 메모리 파일에 실제로 해당 선호도가 포함되어 있는가?
각 어설션(assertion)은 트레이스(trace)의 서로 다른 부분을 필요로 합니다. 전체 궤적(trajectory)과 상태 변화(state changes)를 캡처하지 않고서는 이러한 차원들을 평가할 수 없습니다.
3. 멀티턴 평가 (Multi-turn evaluation): 현실적인 대화 흐름
일부 에이전트의 동작은 여러 번의 턴(multiple turns)을 거쳐야만 나타납니다. 에이전트가 5턴까지는 문맥(context)을 올바르게 유지하다가 6번째 턴에서 실패할 수도 있으며, 개별 요청은 잘 처리하지만 요청들이 서로 누적될 때는 어려움을 겪을 수도 있습니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 LangChain Blog의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기