게임 개발을 위한 머신러닝 활용하기
요약
게임 디자이너의 반복적인 밸런스 조정 작업을 효율화하기 위해 머신러닝(ML) 모델을 플레이 테스터로 활용하는 접근 방식을 소개합니다. 디지털 카드 게임 프로토타입인 'Chimera'를 통해, 에이전트가 자기 자신과 대결하며 데이터를 수집하고 학습하는 방식을 시연하여 게임의 균형과 재미를 높이는 과정을 보여줍니다.
핵심 포인트
- 머신러닝 에이전트를 플레이 테스터로 활용하여 수백만 번의 시뮬레이션을 통해 게임 밸런스를 효율적으로 조정할 수 있습니다.
- Chimera 게임은 방대한 상태 공간을 가진 불완전 정보 게임으로, 전통적인 수작업 AI로 구현하기 어려운 복잡성을 가집니다.
- CNN(합성곱 신경망)을 사용하여 게임 상태를 이미지 형태로 인코딩하여 전달하는 방식이 가장 우수한 성능을 보였습니다.
- 학습된 모델은 Unity Barracuda를 통해 게임 클라이언트에서 실시간으로 실행될 수 있을 만큼 가볍고 효율적입니다.
2021년 3월 19일
Stadia 소프트웨어 엔지니어인 Ji Hun Kim과 Richard Wu가 게시함
지난 수년간 온라인 멀티플레이어 게임의 인기가 폭발적으로 증가하며 전 세계 수백만 명의 플레이어를 사로잡았습니다. 이러한 인기는 게임 디자이너에 대한 요구 사항도 기하급수적으로 증가시켰습니다. 플레이어들은 게임이 잘 만들어지고 균형이 잡혀 있기를 기대하기 때문입니다. 결국, 단 하나의 전략이 나머지 모든 전략을 이기는 게임은 재미가 없습니다.
긍정적인 게임 플레이 경험을 만들기 위해, 게임 디자이너들은 일반적으로 다음과 같이 반복적으로 게임의 밸런스를 조정합니다:
이 과정은 시간이 많이 소요될 뿐만 아니라 불완전합니다. 게임이 복잡해질수록 미세한 결함이 틈새로 빠져나가기 더 쉽습니다. 게임에 수십 개의 상호 연결된 기술과 플레이 가능한 다양한 역할이 있는 경우가 많을 때, 적절한 균형을 맞추는 것은 더욱 어려워집니다.
오늘 우리는 모델을 플레이 테스터 (play-testers)로 훈련시켜 *게임 밸런스 (game balance)*를 조정하는 머신러닝 (ML) 활용 접근 방식을 소개합니다. 또한, 이전에 ML 생성 예술의 테스트베드로 선보였던 디지털 카드 게임 프로토타입인 Chimera를 통해 이 접근 방식을 시연합니다. 훈련된 에이전트 (agents)를 사용하여 수백만 번의 시뮬레이션을 실행하고 데이터를 수집함으로써, 이 ML 기반 게임 테스트 접근 방식은 게임 디자이너가 게임을 더 재미있고, 균형 잡히고, 원래의 비전에 부합하도록 더욱 효율적으로 만들 수 있게 해줍니다.
우리는 개발 과정에서 머신러닝에 크게 의존하는 게임 프로토타입으로 Chimera를 개발했습니다. 게임 자체의 경우, 가능성 공간 (possibility space)을 확장하도록 규칙을 의도적으로 설계하여, 게임을 플레이하기 위한 전통적인 수작업 AI를 구축하기 어렵게 만들었습니다.
Chimera의 게임 플레이는 플레이어가 강화하고 진화시키고자 하는 목표인 제목 그대로의 키메라(chimeras), 즉 생명체의 혼합물을 중심으로 전개됩니다. 게임의 목표는 상대방의 키메라를 물리치는 것입니다. 다음은 게임 디자인의 핵심 사항입니다:
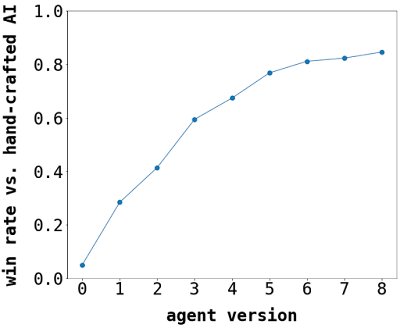
방대한 상태 공간 (state space)을 가진 불완전 정보 카드 게임으로서, 우리는 Chimera가 머신러닝 (ML) 모델이 학습하기 어려운 게임이 될 것이라고 예상했습니다. 특히 우리는 비교적 단순한 모델을 목표로 하고 있었기 때문입니다. 우리는 AlphaGo와 같은 초기 게임 플레이 에이전트들이 사용했던 방식에서 영감을 얻은 접근법을 사용했습니다. 이 방식은 합성곱 신경망 (CNN)을 사용하여 임의의 게임 상태가 주어졌을 때 승리 확률을 예측하도록 학습시키는 것입니다. 무작위 동작을 선택하는 게임을 통해 초기 모델을 학습시킨 후, 에이전트가 자기 자신과 대결하도록 설정하여 게임 데이터를 반복적으로 수집하였고, 이를 다시 새로운 에이전트를 학습시키는 데 사용했습니다. 반복이 거듭될수록 학습 데이터의 품질이 향상되었으며, 게임을 플레이하는 에이전트의 능력 또한 향상되었습니다.
| 학습이 진행됨에 따라 우리가 직접 제작한 최적의 AI를 상대로 보여준 ML 에이전트의 성능. 초기 ML 에이전트 (버전 0)는 무작위로 동작을 선택했습니다. |
모델이 입력값으로 받게 될 실제 게임 상태 표현 (state representation)에 대해서는, CNN에 인코딩된 "이미지"를 전달하는 것이 모든 벤치마크 절차적 에이전트 (procedural agents) 및 다른 유형의 네트워크 (예: 완전 연결 (fully connected) 네트워크)를 능가하는 가장 좋은 성능을 보인다는 것을 발견했습니다. 선택된 모델 아키텍처는 CPU에서 합리적인 시간 내에 실행될 수 있을 만큼 충분히 작으며, 덕분에 모델 가중치 (weights)를 다운로드하여 Unity Barracuda를 사용하여 Chimera 게임 클라이언트에서 에이전트를 실시간으로 실행할 수 있었습니다.
| 신경망 학습에 사용된 게임 상태 표현의 예시. |
| 게임 AI를 위한 의사결정을 내리는 것 외에도, 우리는 모델을 사용하여 게임 진행 과정 동안 플레이어의 예상 승률을 표시하는 데에도 사용했습니다. |
이러한 접근 방식 덕분에 우리는 실제 플레이어가 동일한 시간 동안 플레이할 수 있는 양보다 수백만 배 더 많은 게임을 시뮬레이션할 수 있었습니다. 가장 높은 성능을 보이는 에이전트들이 플레이한 게임으로부터 데이터를 수집한 후, 우리는 결과를 분석하여 우리가 설계한 두 플레이어 덱 사이의 불균형을 찾아냈습니다.
먼저, Evasion Link Gen 덱은 플레이어의 키메라 (chimera)를 진화시키는 데 사용되는 추가 링크 에너지 (link energy)를 생성하는 능력을 가진 주문 (spells)과 생물 (creatures)로 구성되었습니다. 또한 생물들이 공격을 회피 (evade)할 수 있게 하는 주문들도 포함되어 있었습니다. 반면, Damage-Heal 덱은 치유 (healing)와 미미한 피해 (damage)를 입히는 데 집중하는 주문과 함께 다양한 강도를 가진 생물들을 포함하고 있었습니다. 우리는 이 덱들이 동일한 강도를 갖도록 설계했음에도 불구하고, Evasion Link Gen 덱이 Damage-Heal 덱을 상대로 플레이했을 때 60%의 승률을 기록했습니다.
바이옴 (biomes), 생물 (creatures), 주문 (spells), 그리고 키메라 진화 (chimera evolutions)와 관련된 다양한 통계 데이터를 수집했을 때, 두 가지 사항이 즉각적으로 눈에 띄었습니다:
이러한 통찰 (insights)을 바탕으로, 우리는 게임에 몇 가지 조정을 가했습니다. 게임의 핵심 메커니즘으로서 키메라 진화를 강조하기 위해, 키메라 진화에 필요한 링크 에너지 (link energy)의 양을 3에서 1로 줄였습니다. 또한 T-Rex 생물에 '쿨다운 (cool-off)' 기간을 추가하여, 해당 생물의 어떤 행동으로부터 회복하는 데 걸리는 시간을 두 배로 늘렸습니다.
업데이트된 규칙으로 '셀프 플레이 (self-play)' 훈련 절차를 반복했을 때, 우리는 이러한 변화가 게임을 원하는 방향으로 유도하고 있음을 관찰했습니다. 즉, 게임당 평균 진화 (evolves) 횟수가 증가했고, T-Rex의 지배력은 약해졌습니다.
T-Rex를 약화시킴으로써, 우리는 Evasion Link Gen 덱이 지나치게 강력한 생물에 의존하던 현상을 성공적으로 줄였습니다. 그럼에도 불구하고, 덱 간의 승률은 50/50이 아닌 60/40 상태로 유지되었습니다. 개별 게임 로그를 자세히 살펴본 결과, 게임 플레이가 우리가 원하는 것보다 전략성이 떨어지는 경우가 많다는 사실이 드러났습니다. 수집된 데이터를 다시 탐색하면서, 우리는 변화를 도입할 수 있는 몇 가지 영역을 추가로 찾아냈습니다.
우선, 두 플레이어 모두의 시작 체력(Health)과 치유 주문(Healing spells)이 회복할 수 있는 체력량을 늘렸습니다. 이는 더 다양한 전략이 번성할 수 있도록 게임 시간을 길게 유도하기 위함이었습니다. 특히, 이를 통해 Damage-Heal 덱이 자신의 치유 전략을 활용할 수 있을 만큼 충분히 오래 생존할 수 있게 되었습니다. 적절한 소환(Summoning)과 전략적인 바이옴(Biome) 배치를 장려하기 위해, 잘못된 바이옴이나 과밀한 바이옴에 생명체를 배치할 때 적용되던 기존의 페널티를 강화했습니다. 마지막으로, 미세한 속성(Attribute) 조정을 통해 가장 강력한 생명체와 가장 약한 생명체 사이의 격차를 줄였습니다.
새로운 조정 사항이 적용된 후, 우리는 이 두 덱에 대한 최종 게임 밸런스 통계에 도달했습니다:
| 덱 | 게임당 평균 진화(Evolves) 횟수 (이전 → 이후) | 승률 (100만 게임 기준) (이전 → 이후) |
|---|---|---|
| Evasion Link Gen | 1.54 → 2.16 | 59.1% → 49.8% |
| Damage Heal | 0.86 → 1.76 | 40.9% → 50.2% |
일반적으로 새로 프로토타입(Prototype)을 만든 게임에서 불균형을 식별하는 데는 수개월의 플레이테스팅(Playtesting)이 소요될 수 있습니다. 하지만 이 접근 방식을 통해 우리는 잠재적인 불균형을 발견했을 뿐만 아니라, 단 며칠 만에 이를 완화하기 위한 미세 조정(Tweaks)을 도입할 수 있었습니다. 우리는 비교적 단순한 신경망(Neural network)만으로도 인간 및 전통적인 게임 AI를 상대로 높은 수준의 성능을 내기에 충분하다는 것을 발견했습니다. 이러한 에이전트(Agents)는 신규 플레이어를 위한 코칭이나 예상치 못한 전략을 발견하는 것과 같은 방식으로 더 다양하게 활용될 수 있습니다. 우리는 이 연구가 게임 개발을 위한 머신러닝 (Machine learning)의 가능성에 대해 더 많은 탐구를 불러일으키기를 바랍니다.
이 프로젝트는 많은 사람과의 협업을 통해 진행되었습니다. Ryan Poplin, Maxwell Hannaman, Taylor Steil, Adam Prins, Michal Todorovic, Xuefan Zhou, Aaron Cammarata, Andeep Toor, Trung Le, Erin Hoffman-John, 그리고 Colin Boswell에게 감사드립니다. 플레이테스팅을 통해 기여하고, 게임 디자인에 대해 조언하며, 귀중한 피드백을 주신 모든 분께 감사드립니다.
AI 자동 생성 콘텐츠
본 콘텐츠는 HN Game Dev의 원문을 AI가 자동으로 요약·번역·분석한 것입니다. 원 저작권은 원저작자에게 있으며, 정확한 내용은 반드시 원문을 확인해 주세요.
원문 바로가기